
(10분 테크톡) 리눅스 메모리 관리
리눅스 메모리 관리
목차
- 메모리가 관리되는 방법
- 리눅스가 메모리를 관리하는 방법
- 메모리 고갈 상황과 CPU 사용률을 체크하는 이유
1. 메모리가 관리되는 방법
1) 메모리
- 메모리는 주소덩러리, 주소로 인덱싱을 하는 커다란 배열
- 컴퓨터가 부팅되면 텅텅 비어있던 메모리에 운영체제나 사용자 프로그램이 배열의 원소처럼 차곡차곡 채워지면서
CPU를 점유할 기회를 노림
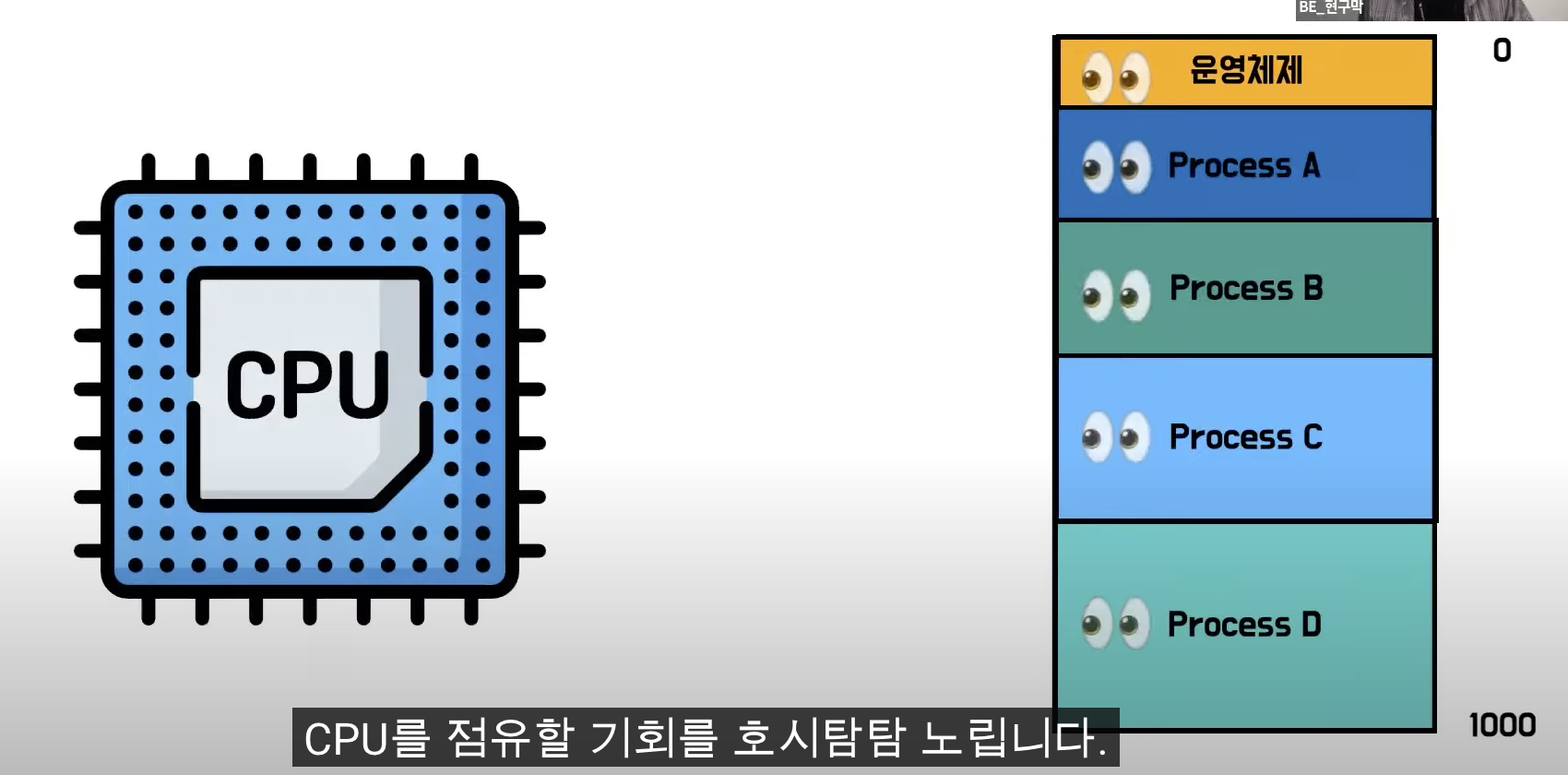
- 기술의 집약체인 CPU가, 메모리에 채워진 프로그램속 코드를 곧장 읽을 수 있으면 좋겠지만,CPU는 코드를 읽지 못함
- 숫자를 바꾸고 나서야 CPU가 우리가 기대하는대로 움직여줌 (코드 읽을수 있음)
2) 주소 변환
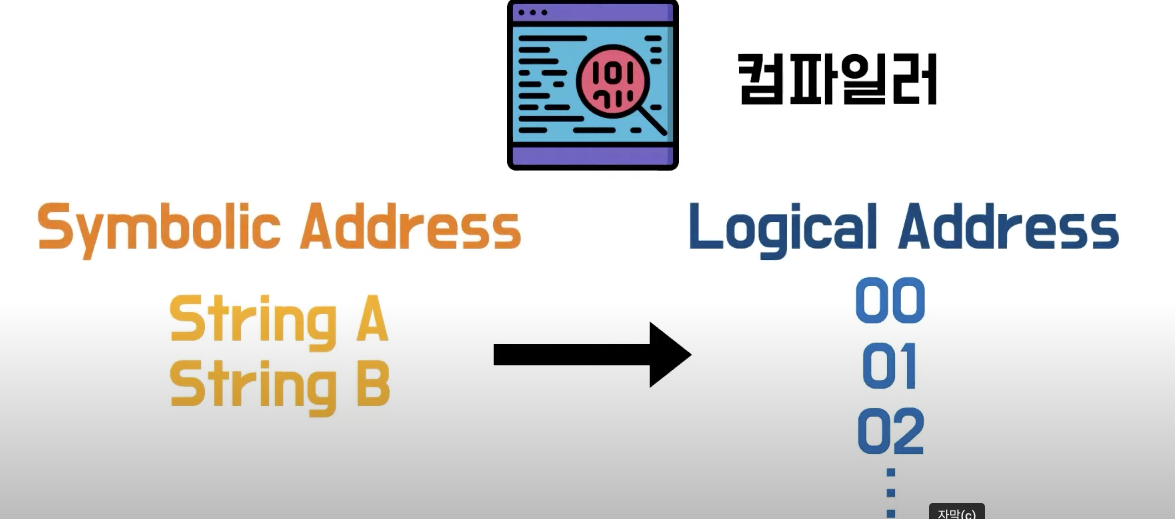
- 코드를 숫자로 바꿔주는 친구가 컴파일러이다.
-
컴파일러가 동작하는 과정에서 코드들의 주소를 결정
- 컴파일러가 변환 시킨 숫자주소를
논리주소라고 부른다. - 각각의 코드마다 중복되는
논리주소가 있기때문에 논리 주소를가상주소라고도 부른다
- 컴파일러가 변환 시킨 숫자주소를
- 그렇다면 모두 같은 주소를 사용한다면 메모리에서 어떻게 이를 구별할까?
- 논리 주소에 하나의 주소값이 더 더해진다.
- 각각 프로그램들의 독립된 주소가 그제서야 생긴다.
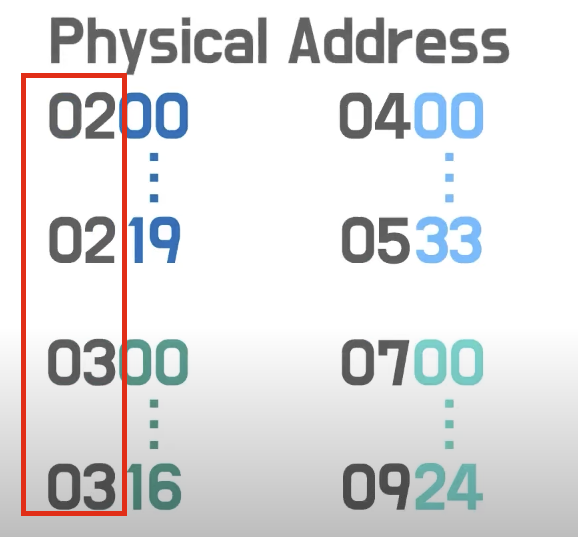
- 이게 메모리에 쌓이는데 이걸
물리주소라고 부른다.
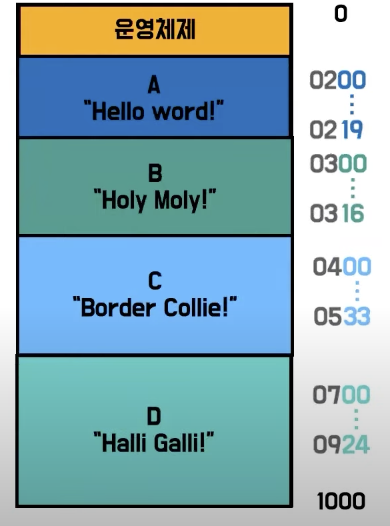
- CPU가 논리주소만 읽기 때문에 논리주소로 변환하는 것이다.
- CPU는 현재 활동중인 프로세스 내부의 주소만 알면 되지, 어떤 프로세스인지는 알수도, 알 필요도 없다.
- CPU가
논리주소를 읽게 도와주는 하드웨어가 MMU(Memory Management Unit)이다.
3) MMU
- 프로그램의 시작주소를 가진 base register 와 마지막 주소를 가진 limit register, 간단한 산술 연산기로 이루어짐
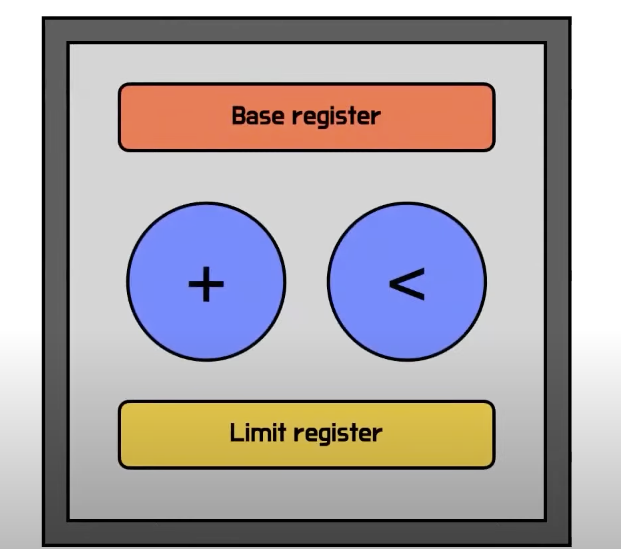
- CPU를 사용중인 프로세스가 요청하는 논리 주소에 base register에 들어있는 시작주소를 더해서
물리주소로 변환- 이렇게 완성된 물리 주소를 메모리에서 프로세스가 가진 정보를 정확하게 찾아 읽어올 수 있게 됨
3-1) base register가 동작하기전에 선행 동작이 필요
- limit register에 들어있는 마지막 주소로 프로세스가 요청하는 논리 주소가 올바른지 확인
- 만약 악의적인 프로그램이 본인의 마지막 주소가 219인데도 불구하고 325번의 번호를 달라고 요청하면 325번의 주소를 줌
- limit register가 이런 오지랖을 부리지 않도록 먼저 체크
- 체크했을때 오지랖을 부렸을 경우 해당 프로세스를 멈추고 CPU 권한을 운영체제에 넘김
- 잠에서 깨어난 운영체제는 이 프로세스가 왜 멈췄는지 살펴보고 악의적인 이유였음이 확인되면 응징함
- limit의 검사를 통과한 경우에만 base register에 저장되어있던 값을 더해서 물리주소에 있는 정보를 읽어올 수 있음
4) 메모리 할당
- 메모리에 프로세스들이 차례대로 예쁘게 채워지고, MMU를 통해 고정된 주소를 한 번씩 더하면서 메모리를 참조하니
메모리에 사용이 간단할 것 같지만, 메모리엔 프로세스들이 이쁘게 채워지지 않음 - 차례차례 프로세스를 쌓을 경우 메모리에 아무도 사용하지 못하는 빈 구멍들이 생김
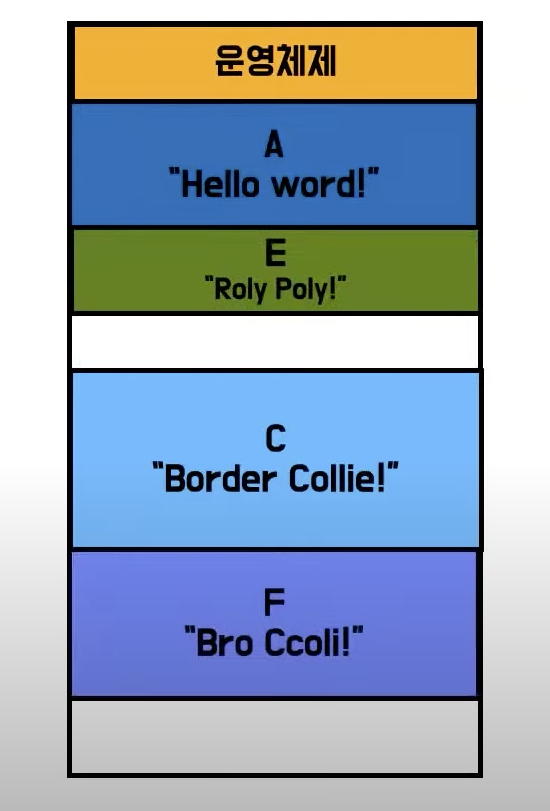
- 남는 공간을 활용하면 G가 들어올수 있지만 프로그램 G는 메모리에 올라 오지 못함
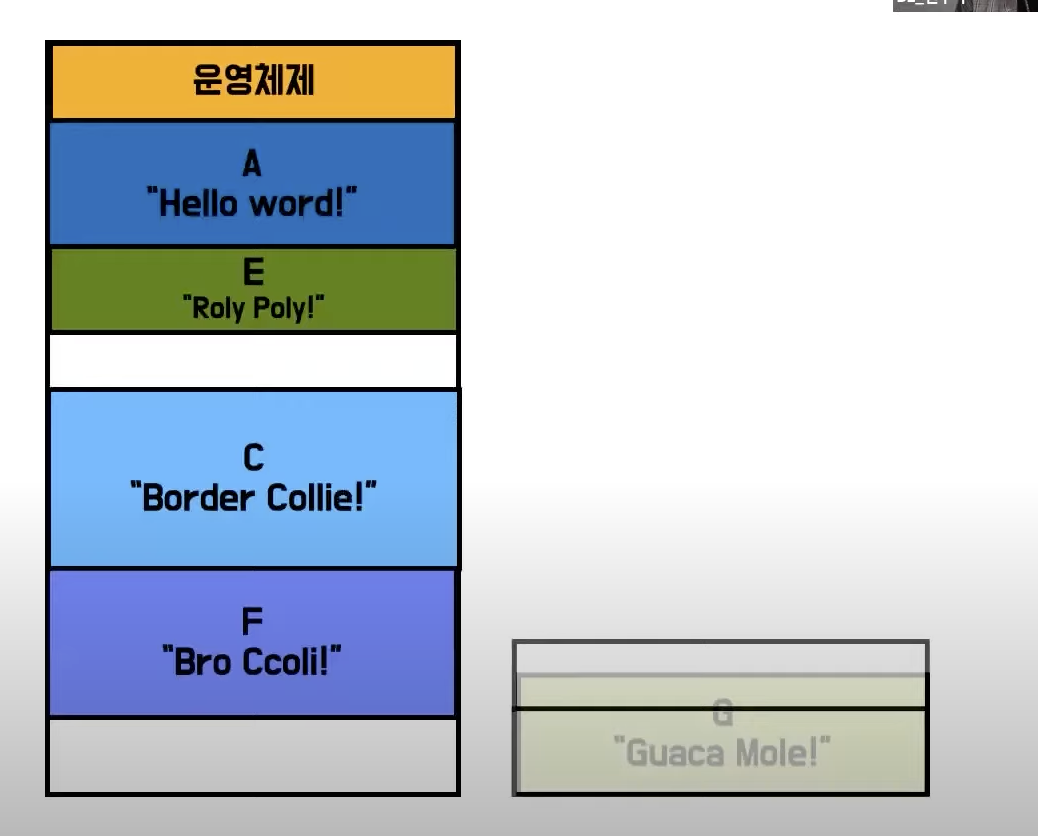
- 그래서 Swapping 기법을 사용
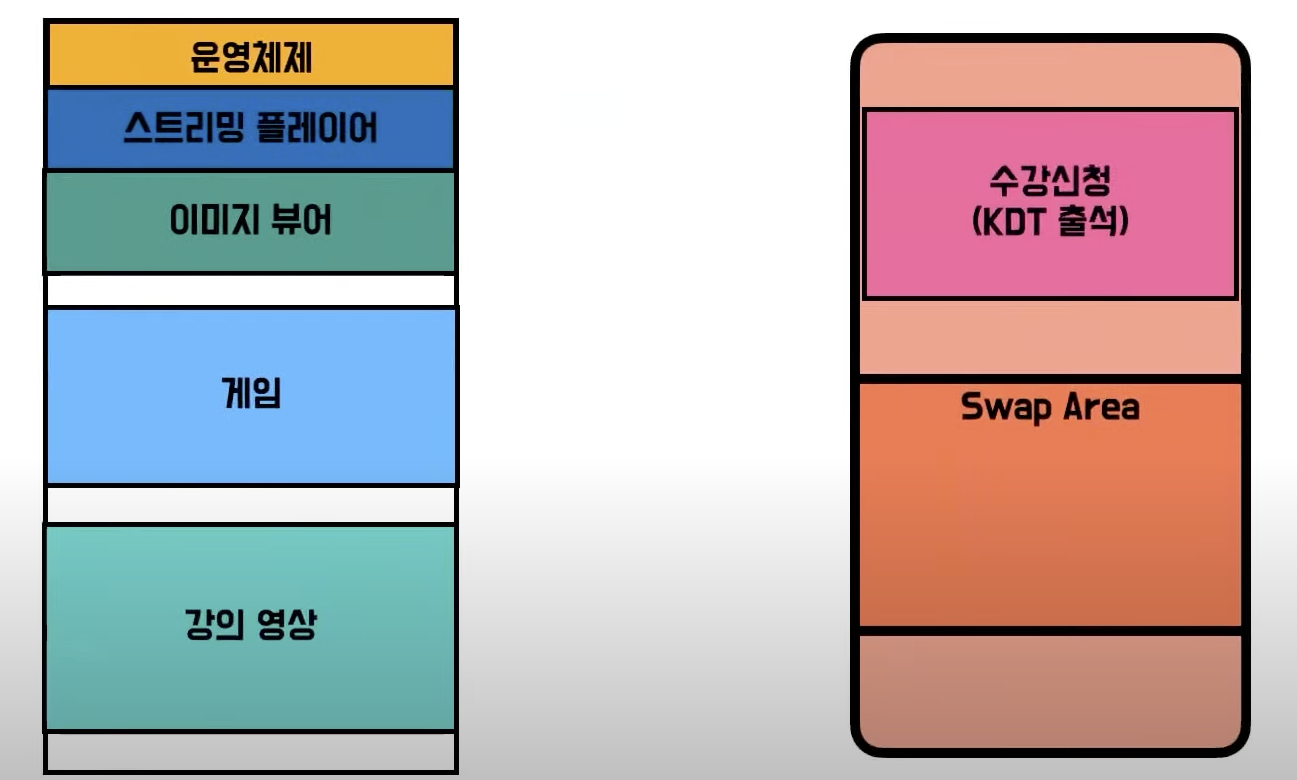
5) Swapping
- Swapping 기법도 만능은 아님
- 중요도에 따라 Swapping할 프로세스를 고르려 해도 프로세스를 하나씩 전부 검사해야해서 시간도 걸림
- 중요도 계산을 끝내고 프로세스를 옮긴다고 해도 단순하게 작은 파일을 주고 받는것과 달리 많은 시간이 걸림
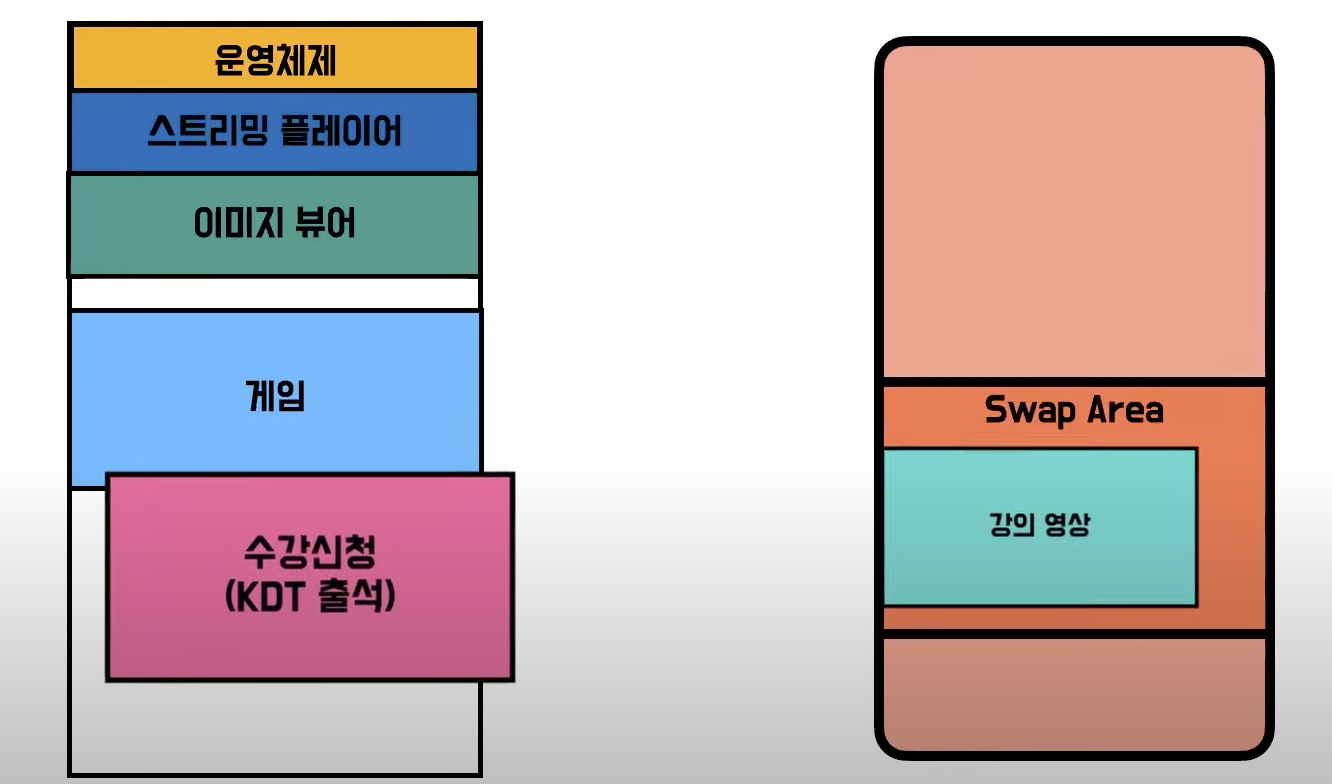
- Swapping 기법과 함께 메모리에 공간을 최대한 활용하고자 미리 메모리를 적당하게 나눠놓기 (왼쪽)
- 올라오는 프로그램에 맞춰 최적의 크기를 찾아 할당하기 (오른쪽)
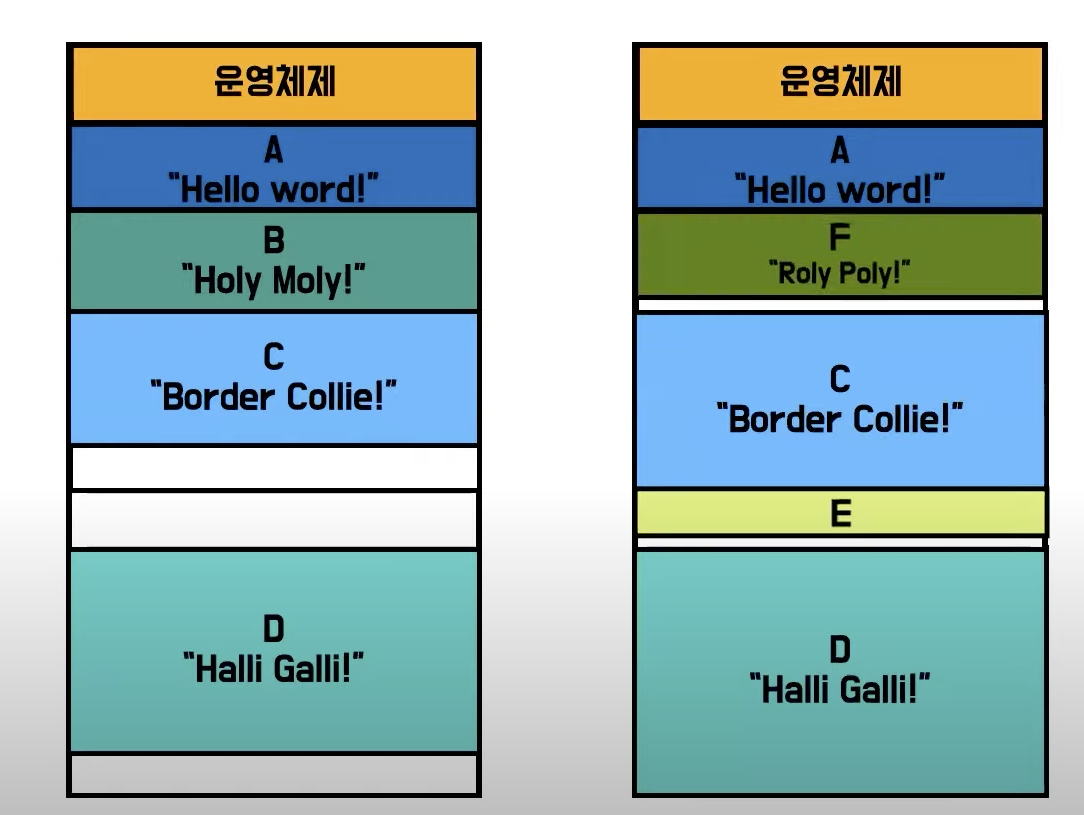
- 그래서 일정하게 나누고 그에 맞춰 프로그램을 조금씩 잘라서 올리자는 결론애 이름
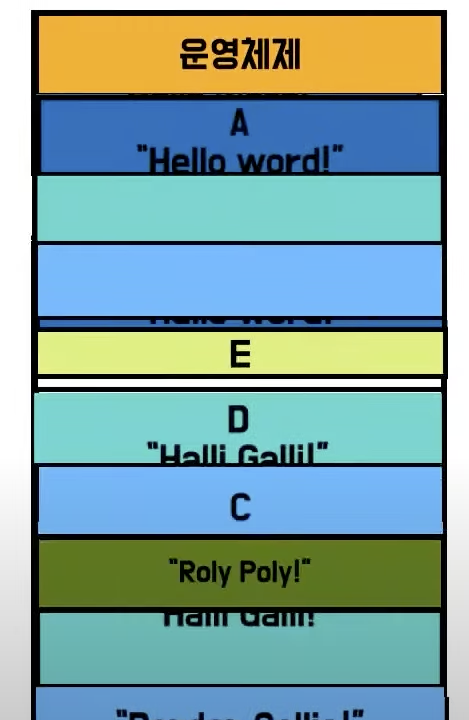
- 프로그램을 조금씩 잘라 올리기 위해 우선 물리적인 메모리를 동일한 크기로 나눔
- 이 공간들을
Frame이라고 부름
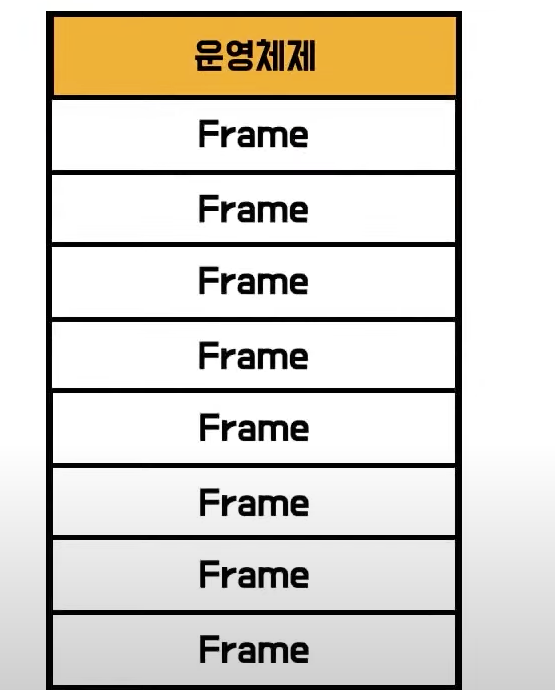
- 그리고 프로그램을 Frame과 동일한 크기로 자름
- 잘린것 하나하나를 Page라고 부름
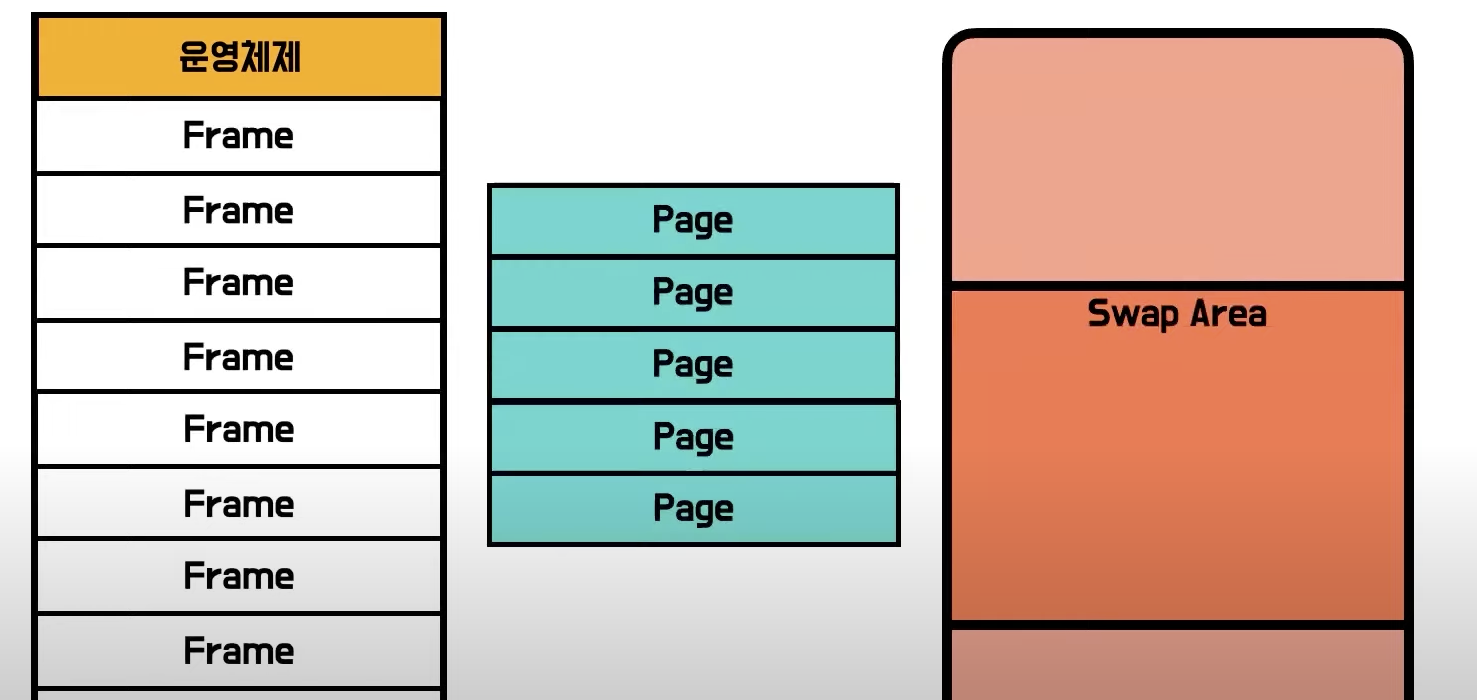
- 잘려진 Page들 중에 당장 프로그램이 동작하는데 필요한 최소한의 page들만 메모리에 올리고 나머지는 swap공간에 저장
- 이것이 Paging 기법
6) Paging
-
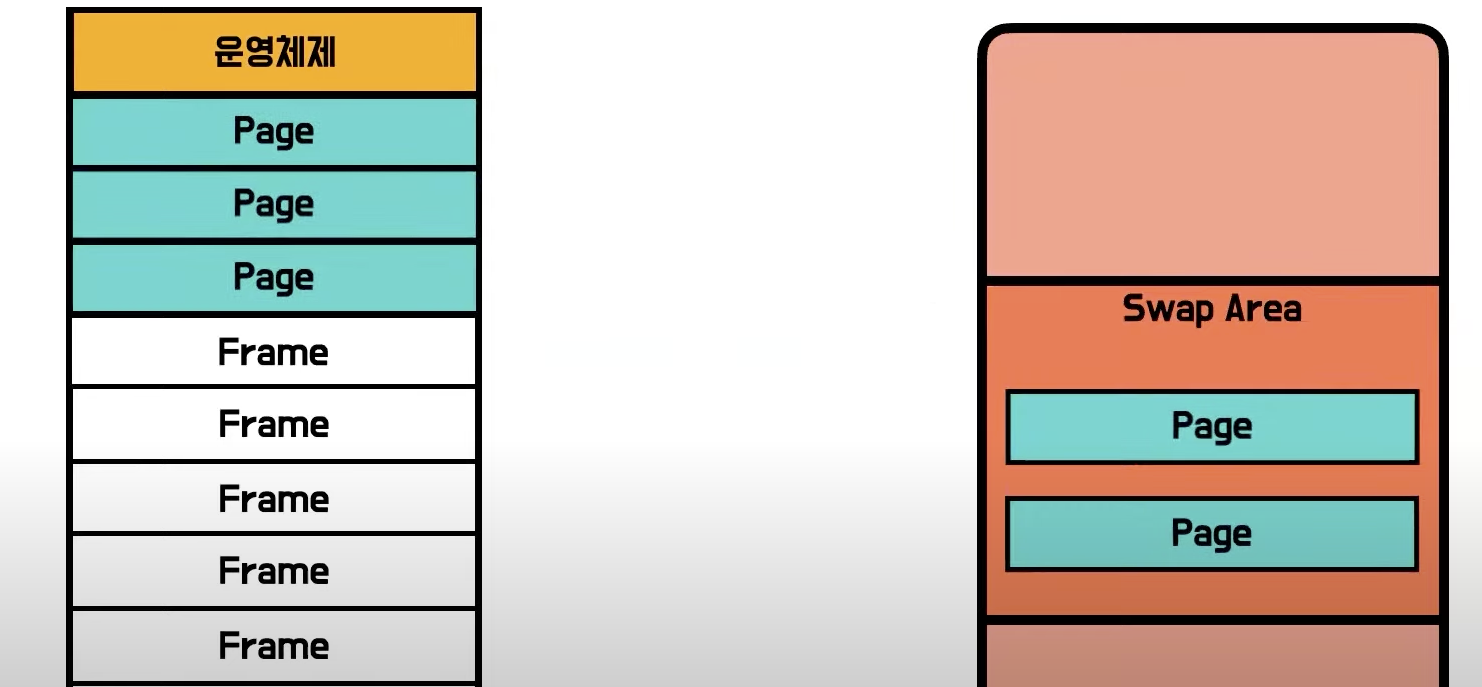
페이징 기법으로 인해 메모리의 낭비는 없어졌지만 한 프로그램의 page가 메모리에 여기저기 분포하게 되었다.
- 순서도 보장할 수 없음
- MMU 계산도 복잡해짐

- 논리주소 - 물리주소 변환을 위한 별도의 Page Table을 사용
- Page Table때문에 MMU 레지스터들의 이름과 용도도 조금씩 달라짐
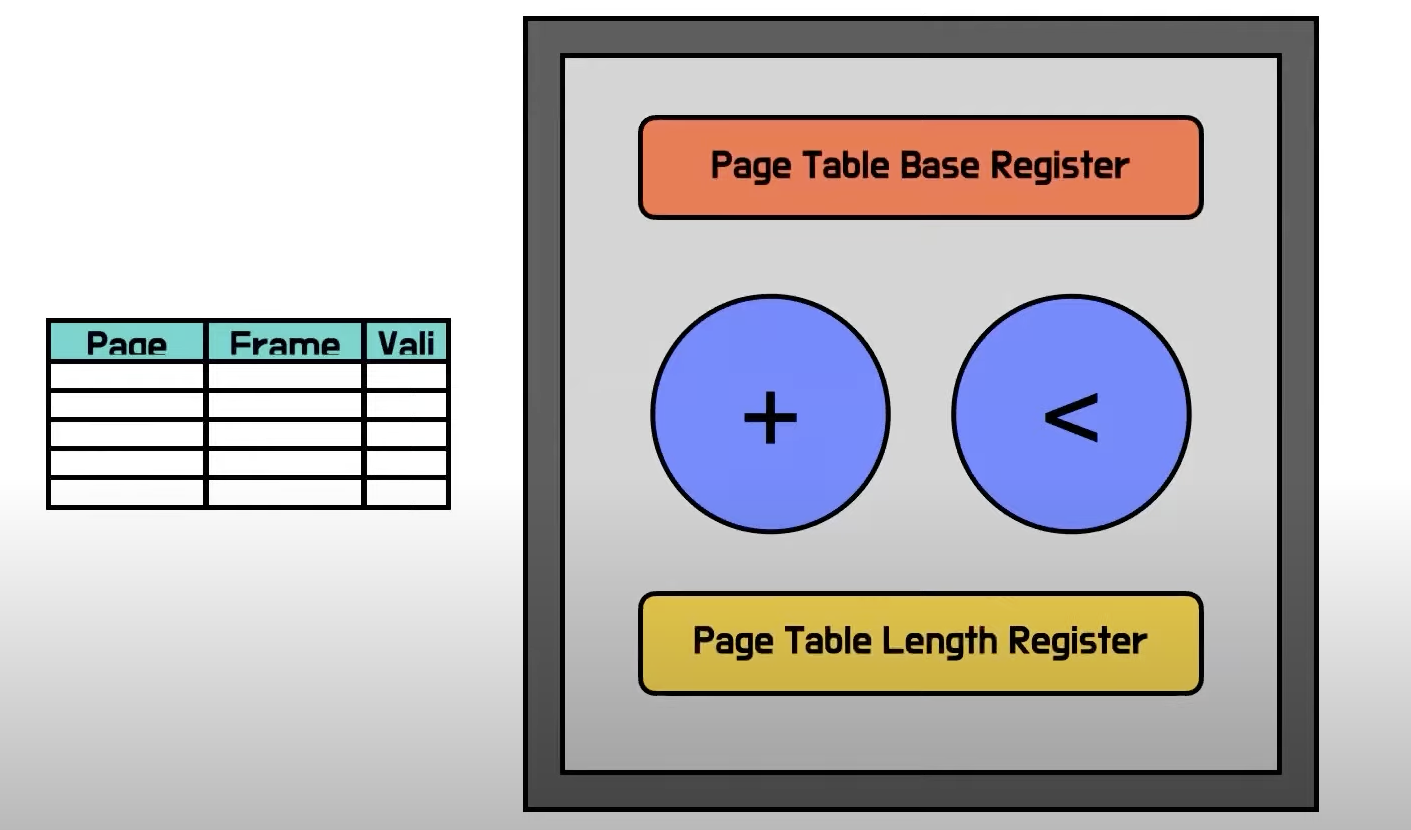
- 이전에 프로세스의 시작주소를 더해주던 base register는 Page table의 시작주소를 더해주고 있고,
- 프로세스의 마지막 주소를 검증하던 Limit register는 Page table의 크기를 검증하고 있음
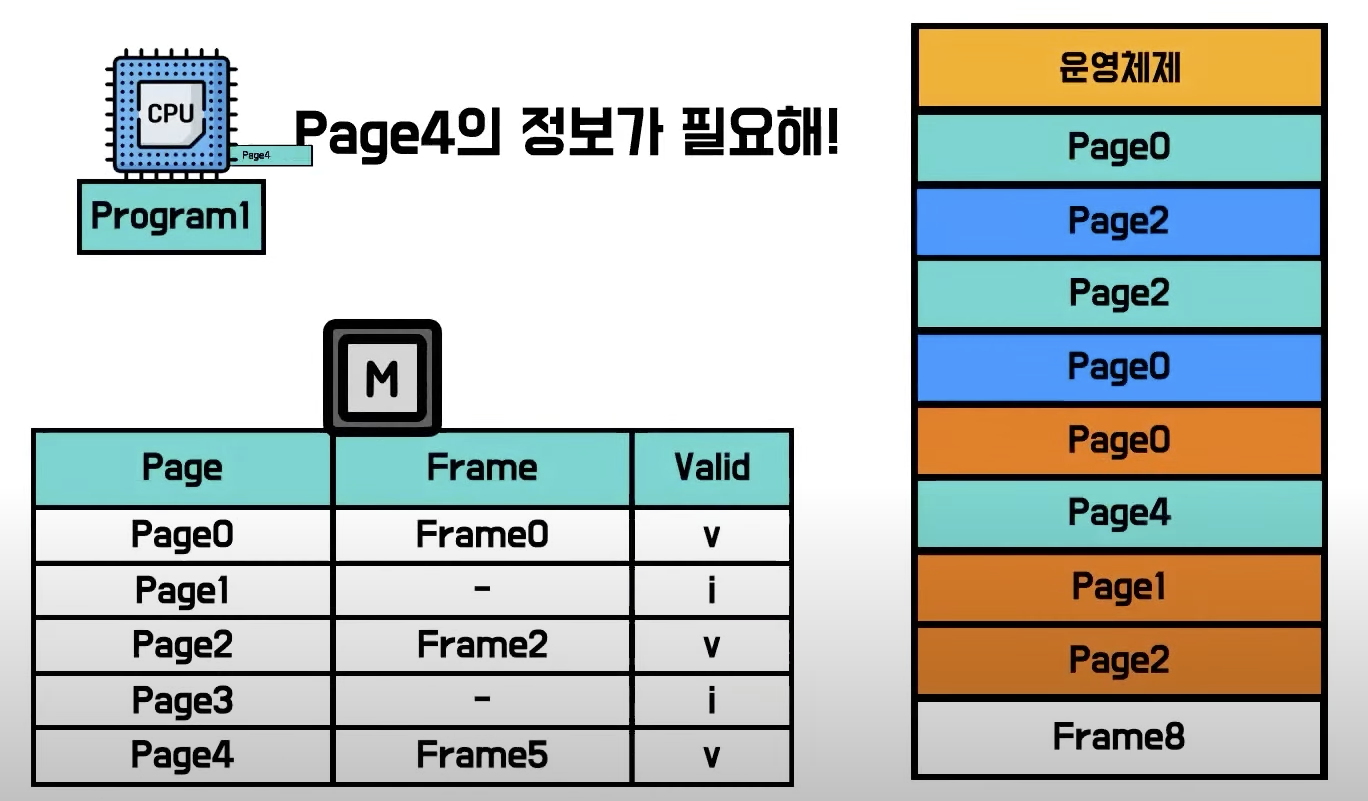
- CPU가 MMU한테 논리적인 주소로 요청을 하게 되면 계산이 끝난값으로 Page table을 참조해서 찾아낸 Frame 주소로
이동해 해당 Page의 정보를 읽어옴
6-1) 그렇다면 page table은 어디에 저장될까?
- 우선, 페이지 테이블의 행 개수는 해당 프로그램의 크기를 일정한 간격으로 나눈 수 이다.
- 백만개가 넘는 행을 가진 테이블이 프로세스마다 1개씩 존재하는데 이걸 CPU에 저장할 수는 없다.
- 그래서 메모리에 저장
- 메모리 공간을 알차게 사용하자고 페이징 기법을 적용했는데 Page table이 공간을 차지하고 있음
- 메모리에 공간을 효율적으로 사용하고자 프로세스들끼리 공통되게 사용하는 부분을 생각함
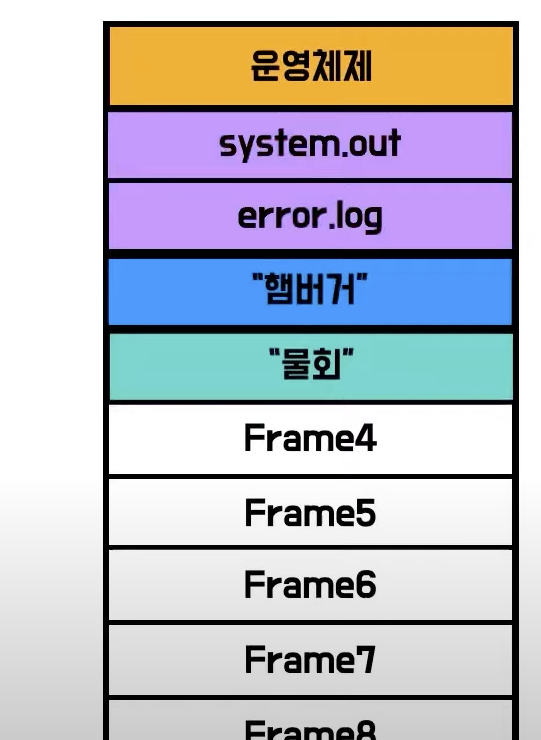
-
system.out 같은 frame을 공통적으로 사용하는 프로세스들이 나눠쓰게 만듬
- 공용적으로 사용하는 페이지, Shared page라는 이름을 붙임
- 절대 변하면 안되기 때문에 Read-Only 권한을 부여
- 또, 각각의 프로그램들이 쉽게쉽게 찾을 수 있도록 서로 동일한 논리주소에 위치해야 한다.
- 이 두가지 조건중 하나라도 일치하지 않으면 shared page로서 사용될 수 없다.
-
Page table, frame 모두 메모리에 위치해 있기때문에 속도가 느려진다.
- 이것을 극복하기위해 추가적으로 하드웨어를 지원받는다. (TLB)
7) TLB (translation look-aside buffers)
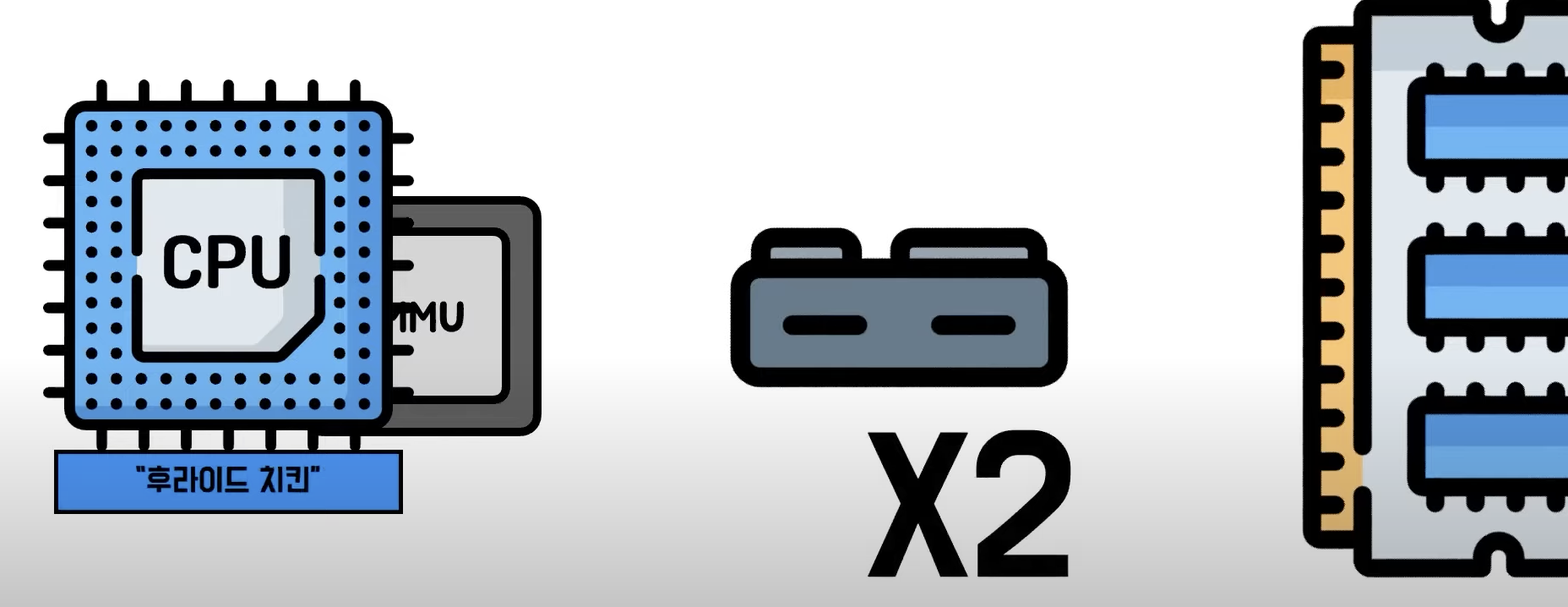
- 캐시 메모리이다.
- 병렬적으로 한꺼번에 자신이 가진 정보를 조회
- 작고, 빠르고, 속도 향상을 위해서 존재
- CPU가 논리 주소로 정보를 요청하면 Page table에 접근하기전, 우선 TLB부터 확인
- TLB에 주소가있으면 TLB에 있는 Frame 주소로 바로 변환을 진행하고, 메인 메모리에서 가져옴
- TLB에 주소가 없으면 그제서야 Page table을 참고해서 주소 변환을 진행
- 대부분의 프로세스는 한 번 참조했던 곳을 다시 참조할 가능성이 굉장히 높아짐
- 때문에 TLB 참조 성공 확률이 대단히 높아짐
8) 정리
- 현대 메모리는 Paging을 베이스로한 기법을 채택
- 하드디스크를 Swap area로 활용한다.
- MMU, TLB같은 하드우에어들의 지원을 받아 Page Table을 확인하고 메모리를 참조한다.
2. 리눅스가 메모리를 관리하는 방법
1) 운영체제의 역할 (리눅스)
- 가상 메모리로 사용자 프로세스 속이기
- I/O 장치 관리
2) 가상 메모리로 사용자 프로세스 속이기
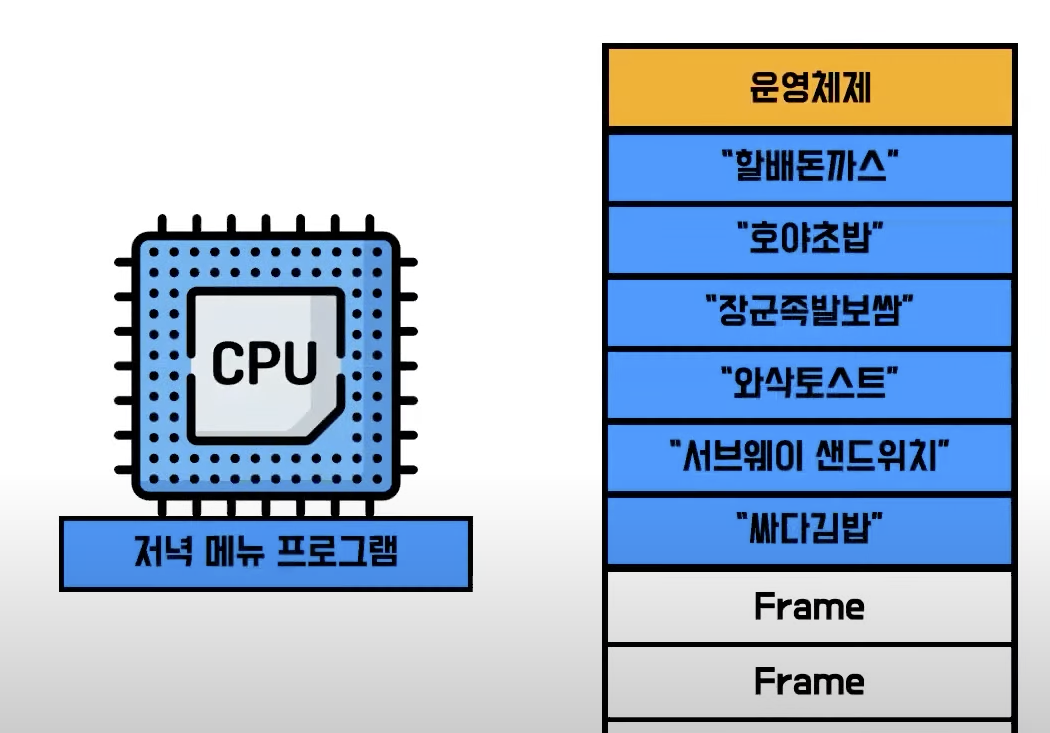
- CPU를 점유중인 프로세스는 자신이 커다랗고 온전한 메모리에 올라있다고 생각함
- 그래서 에러를 내지 않고 정상적으로 잘 동작함
- 그러나 실제론 현재 동작에 필요한 부분만 물리 메모리, 나머지는 SWAP 공간에 저장되어 있음
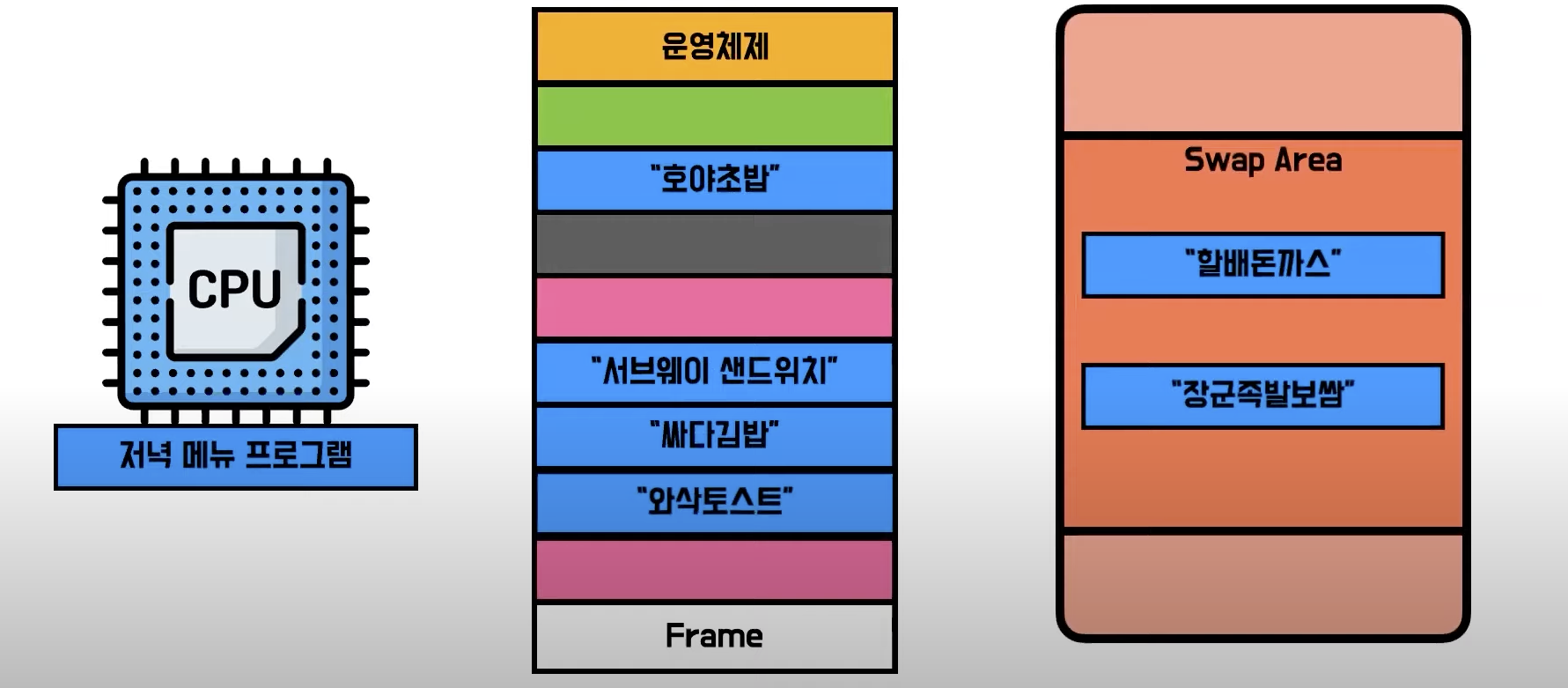
- 이렇게 물리 메모리 공간과 Swap 공간을 합쳐서 만들어낸 가짜 메모리를
가상메모리라고 부름 - 페이징 기법중 CPU를 통해 요구하던 논리 주소가 사실 이 가상 메모리의 주소,
가상 주소엿음
3) I/O 장치 관리
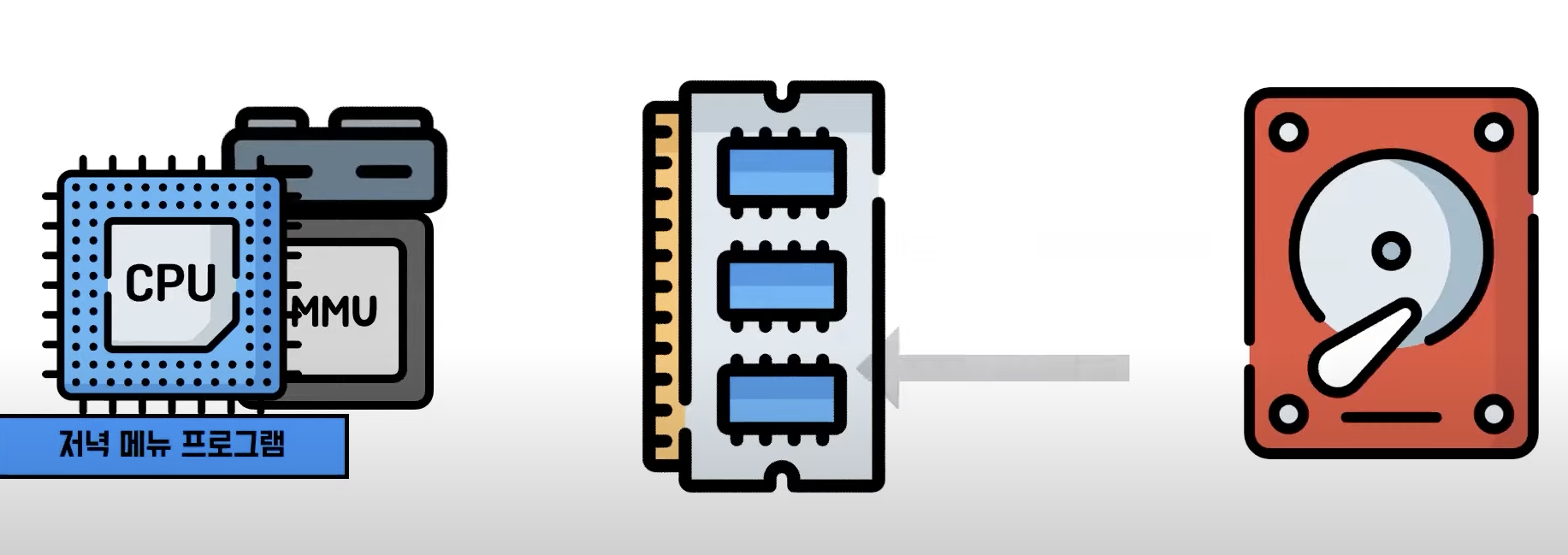
- 주소를 변환하고 메모리에서 Page를 찾아내는건 사용자 프로세스와 하드웨어에서 진행하지만,
- 하드디스크 같은 입출력 장치를 건드리는 것은 운영체제의 역할 이다.
- 즉, SWAP 공간에서 page를 꺼내려면 운영체의 도움이 필요
4) Page fault
- 프로새스가 CPU를 점유하고 한참 작업을 이어나가던 중에, TLB와 메모리에 없는 페이지를 요구
- 메모리에 페이지가 없다는걸 알아차린 MMU는 프로세스를 일시 정지 시킴
- 운영체제가 잠에서 깨어나 CPU를 점령하고 왜 프로세스가 멈췄는지 다시 한번 체크함
- 만약 이상한 주소를 요청한거라면 바로 처단
- 아니라면 운영체제가 하드디스크의 SWap 공간에서 페이지를 메모리로 가져오고, TLB에 주소를 등록해줌
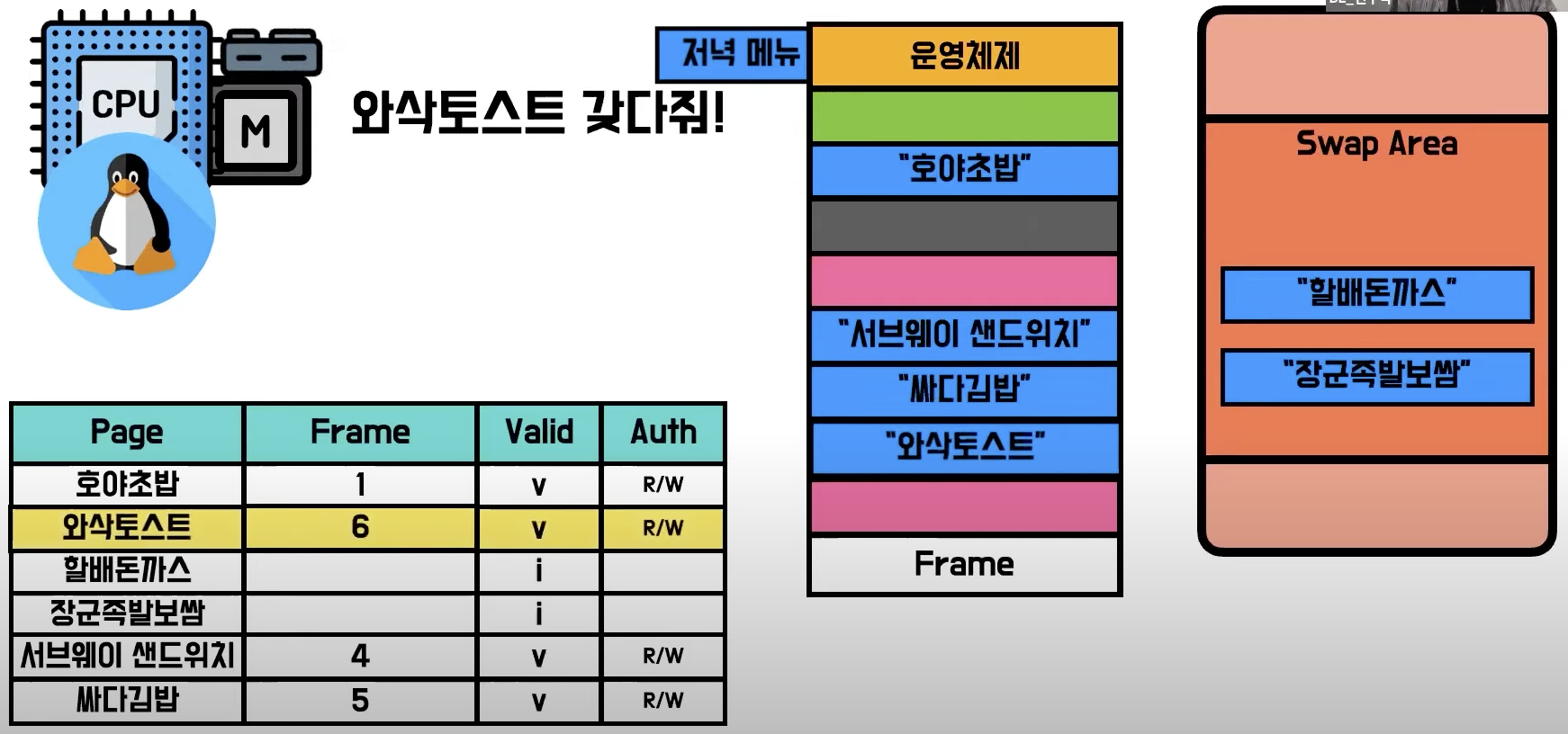
- Page table에 valid bit도 함께 업데이트
- 그 후 운영체제는 CPU를 내놓고 다시 잠에 듬
4-1) 이 기간이 엄청 길기때문에 다른 프로세스가 CPU를 점유할 수 있음
- 이럴 경우 기존 프로세스는 대기 큐에 들어가서 다시 자기 차례를 기다림
- 명령 수행을 실패한 지점부터 동작을 수행하게 됨
- page fault가 발생하면 CPU다른 프로세스로 넘어갈 만큼 굉장히 많은 시간이 소모된다는 걸 알 수 있음
- 이 때문에 page fault 확률이 곧 성능이 된다.
- 중복된 내용의 참조가 많아서 fault 확률이 낮음
- 대부분의 경우 TLB을 참조하면서 굉장히 빠르게 작업이 진행됨
5) Page replacement
- CPU가 계속 작업을 진행하면서 page fault 때문에 SWAP 공간에서 페이지를 가져오다가, 물리 메모리의 frame이
가득차게 되면 어떻게 해야할까? - 다음 page fault 때 하드디스크에서 페이지를 메모리로 올리기 위해 기존 메모리의 frame을 차지한 page 중 하나를
내쫓아야함- 이 행위를 page replacement 라고함
- 어떤 페이지를 replacement할지는 운영체제가 결정
5-1) 쫓아낼 페이지를 선정하는 방법
- LRU, 마지막으로 참조된 시점에 가장 오래된 페이지를 찾아내는 알고리즘이 적합
- 그런데 운영체제는 이미 물리 메모리에 있었으면서 page fault를 회피한 page들에 대한 정보는 알수 없음
- 자신이 page fault를 관리했던 사항만 기억할 수 있음
- 그래서 Clock algorithm 을 사용
6) Clock algorithm
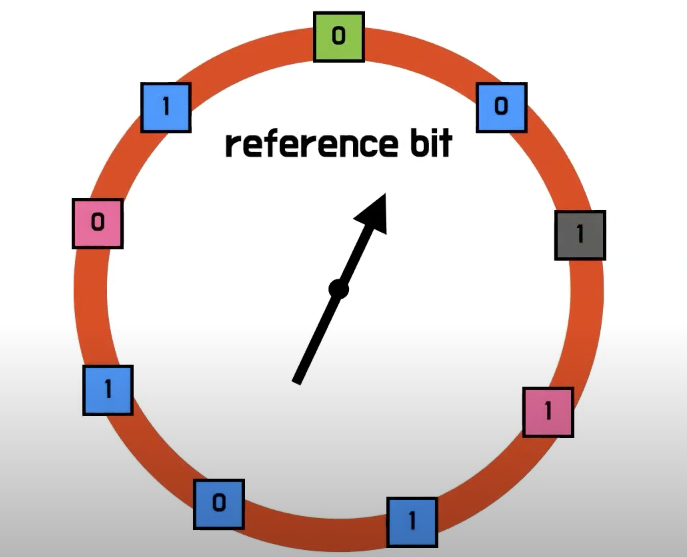
- 메모리에 올라와 있는 모든 page 마다 1개의 reference bit를 갖게 함
- 초기에는 모두 0이다가, CPU를 점유중인 프로세스로부터 참조되면 bit가 1로 올라감
- 이 상태에서 page replacement가 진행될 경우 한쪽 방향으로 페이지 테이블을 참조하기 시작함
- 참조하는 과정에서 1bit를 만나면 0bit으로 내리고, 0bit을 만나면 그게 바로 replacement 대상
- 가장 오래동안 참조되지 않은 페이지는 잡아내지 못하지만, 가장 최근에 참조된 페이지는 피할 수 있는 LRU와 근사한 알고리즘
- Clock algorithm은 운영체제가 하드웨어의 도움을 받는 알고리즘
7) Thrashing
- 시간이 지나면서 CPU의 점유율이 떨어지면서 replacement 현상이 자주 발생함 이 현상을 Thrashing이라고함
- Thrasing을 해소하기 위해 Working-set 알고리즘과 Page Fault Frequency 알고리즘을 사용
7-1) Working-set 알고리즘
- 대부분의 프로세스가 일정한 페이지만 집중적으로 참조한다는 성격을 이용
- 특정시간동안 참조되는 페이지의 개수를 파악
- 그 페이지 개수만큼 Frame이 확보되면 그 때 Page들을 메모리에 올리는 알고리즘
만약 Page가 3개 필요한데 Frame을 2개밖에 못주겠다면?
- 2개를 올리지않고 swap 공간에서 기다림
- 그러다가 Frame이 3개 확보되면 그때 올라옴
- Frame이 가득차서 replacement가 진행되면 프로세스마다의 working-set 단위로 page를 쫓아냄
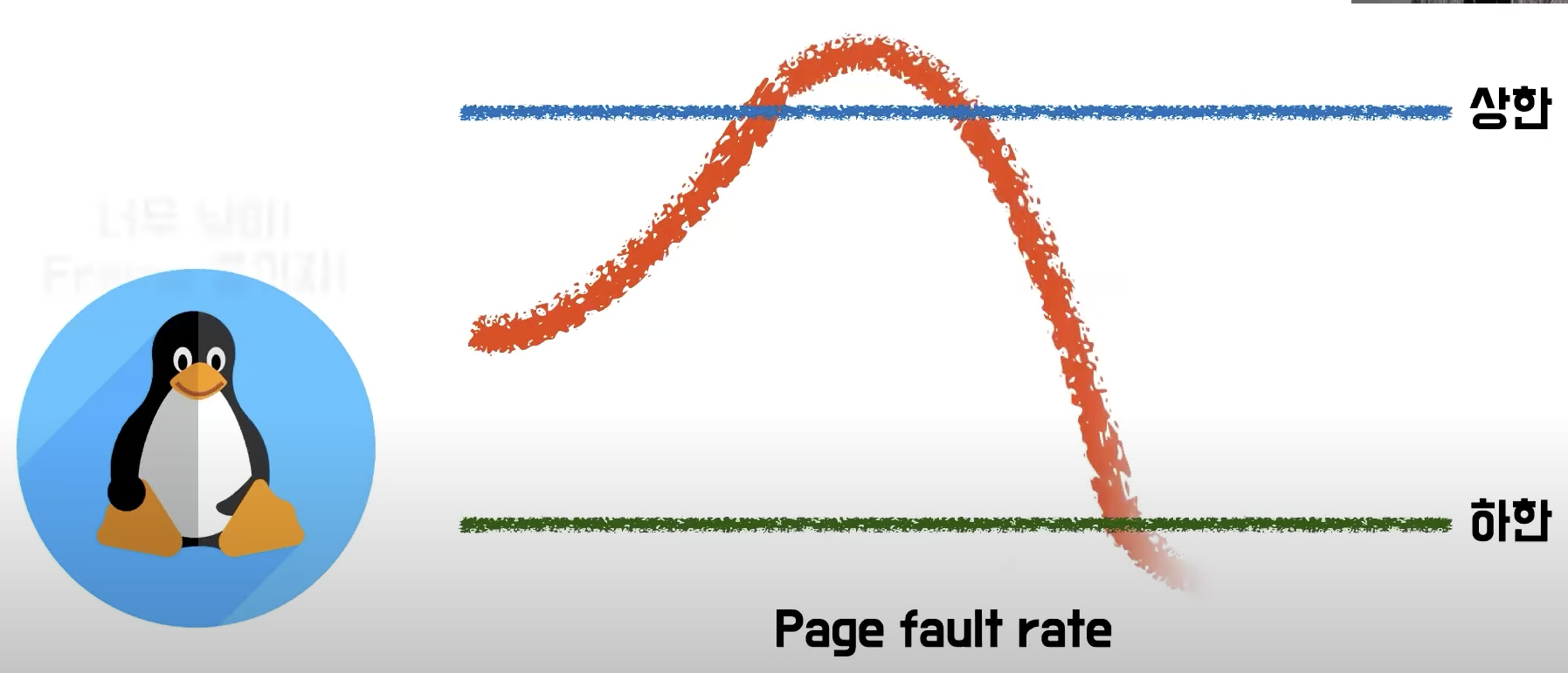
7-2) Page Fault Frequency 알고리즘
- page fault 퍼센트에 상한과 하한을 둠
- 상한선을 넘으면 지급하는 frame의 개수를 늘리고, 하한을 넘으면 줄임
- 이 알고리즘도 남는 frame이 없으면 프로세스 단위로 page들을 통째로 내쫓음
3. 메모리 고갈 상황과 CPU사용률을 체크하는 이유
1) 메모리가 고갈되면 어떤 현상이 발생할까요?
- 프로세스들의 Swap이 활발해지면서 CPU 사용률 하락
- 운영체제가 프로세스 추가, 쓰레싱 발생
- 쓰레싱이 해소되지 않을 경우 Ouf of Memory 상태로 판단
- 중요도가 낮은 프로세스를 찾아 강제 종료
2) CPU 사용률을 계속해서 체크하는 이유
- 특정 시점만 체크한 경우 CPU 사용률이 높아보일 수 있음
- 연속 체크시 CPU 사용률이 급격하게 떨어지는 구간 발견 가능성
- 메모리 적재량을 함께 체크하면서 쓰레싱 유무 확인
- 추가적인 서버자원을 배치하는 등 해결방안을 마련
댓글남기기