자료 구조 - 단순 연결 리스트 2
1. 단순 연결 리스트의 삽입 알고리즘
1) 첫 번째 노드로 삽입하기
insertFirstNode(L, x)
new <- getNode(); // (1)
new.data <- x; // (2)
new.link <- L; // (3)
L <- new // (4)
end insertFirstNode()
(1) 삽입할 노드를 자유 공간 리스트에서 할당 받음
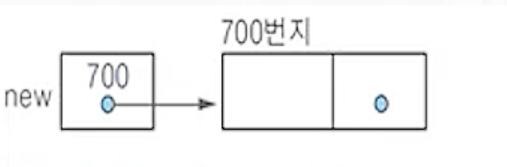
(2) 새 노드의 데이터 필드에 x를 저장함
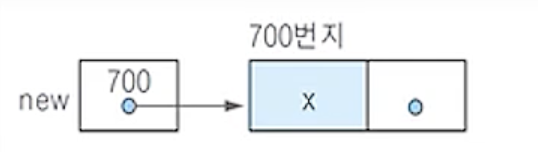
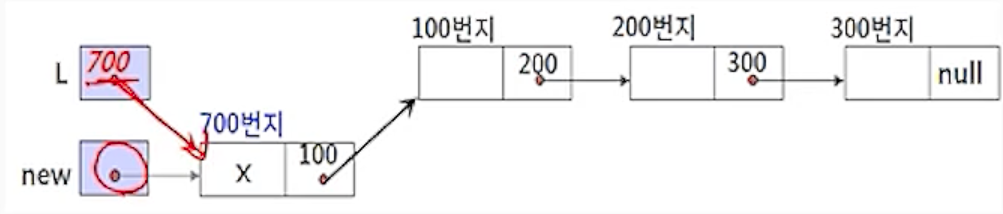
(3) new.link <- L;
- 삽입할 노드를 연결하기 위해서 리스트의 첫 번째 노드 주소(L,100)를 삽입할 새 노드 new의
링크 필드(new.link)에 저장하여 새 노드 new가 리스트의 첫 번째 노드를 가리키게 함

(4) L <- new;
- 리스트의 첫 번째 노드 주소를 저장하고 있는 포인터 L에 새 노드의 주소 (new,700)을 저장하여 포인터
L이 새 노드를 리스트의 첫 번째 노드로 가리키도록 연결함.
2) 중간 노드로 삽입하기
- 리스트 L에서 포인터변수 pre가 가리키고 있는 노드의 다음에 데이터 필드값인 x인 새 노드를 삽입하는
알고리즘
insertMiddleNode(L, pre, x)
new <- getNode();
new.data <- x;
if(L = null) then{ // (1) 공백 리스트 일 경우
L<- new; // (1-1)
new.link <- null; // (1-2)
}
else{ // (2) 공백 리스트가 아닐 경우
new.link <- pre.link; // (2-1)
pre.link <- new; // (2-2)
}
end insertMiddleNode()
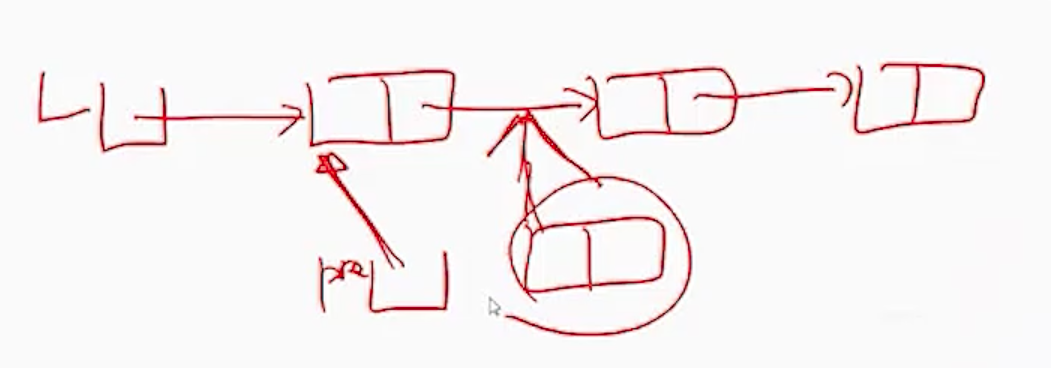
(1) 리스트 L이 공백인 경우
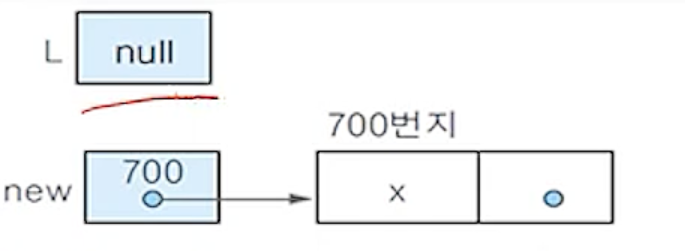
(1-1) L <- new;
- 리스트 포인터 L에 새 노드 new의 주소(700)를 저장하여 new가 리스트의 첫 번째 노드가 되도록 함.
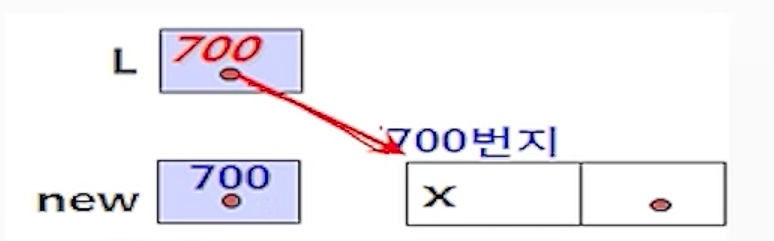
(1-2) new.link <- null;
- 리스트의 마지막 노드인 new의 링크 필드에 null를 저장하여 마지막 노드임을 표시함
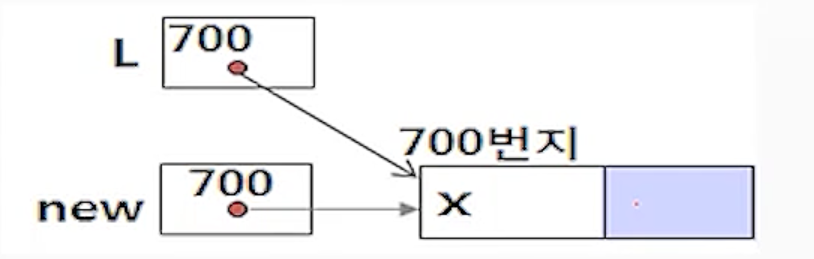
(2) 리스트 L이 공백이 아닌경우
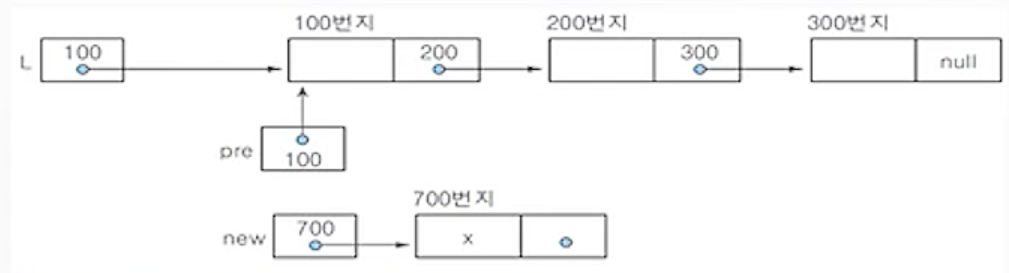
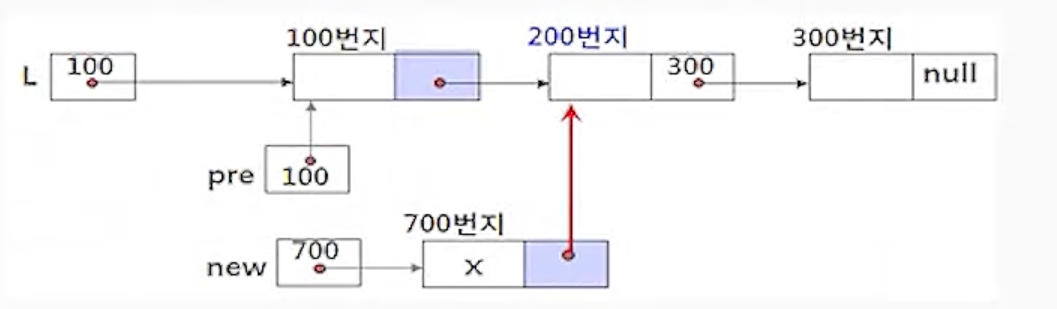
(2-1) new.link <- pre.link;
- 포인터 pre가 기리키는 노드의 다음 노드로 새 노드 new를 연결해야 하므로
pre의 링크 필드값(200)을 노드 new의 링크 필드에 저장하여 새 노드 new가 노드 pre의 다음 노드를
가리키도록 함.
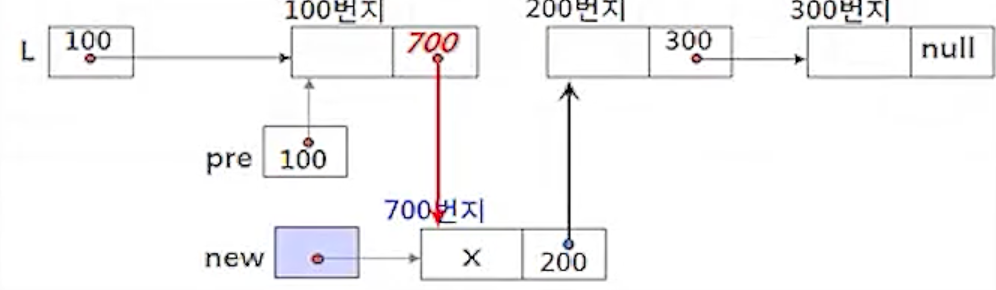
(2-2) pre.link <- new;
- 포인터 new의 값(700)을 노드 pre의 링크 필드에 저장하여 노드 pre가 새 노드 new로 연결되도록 함
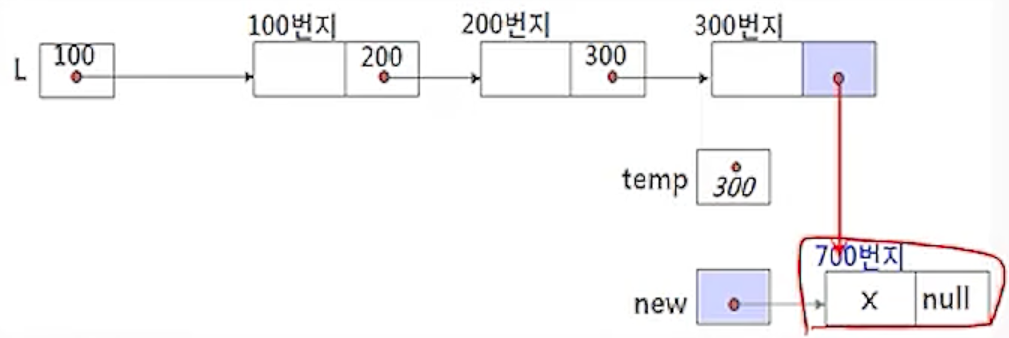
3) 마지막 노드로 삽입하기
insertLastNode(L, x)
new <- getNode();
new.data <- x;
new.link <- null;
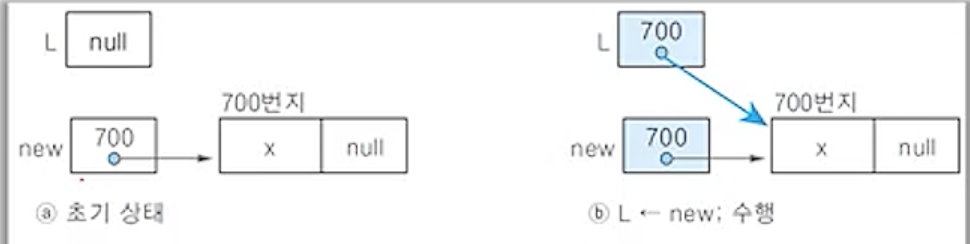
if(L = null) then{ // (1) 공백 리스트 인경우
L <- new;
return;
} // (2) 공백리스트가 아닌 경우
temp <- L; // (2-1)
while(temp.link != null) do
temp <- temp.link; // (2-2)
tem.link <- new; // (2-3)
end insertLastNode()
- 링크 필드가 null인 노드가 마지막 노드
- 리스트에 노드를 순회하는 임시 포인터 temp가 필요
(1) 리스트 L이 공백인 경우
- 중간 노드 삽입 알고리즘의 공백 리스트에 노드 삽입하는 연산과 동일
- 삽입하는 새 노드 new는 리스트 L의 첫 번째 노드이자 마지막 노드
(2) 리스트 L이 공백이 아닌 경우
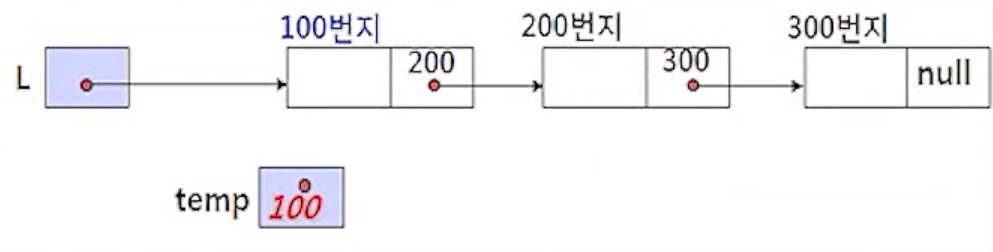
(2-1) temp <- L;
- 현재 리스트 L이 마지막 노드를 찾기 위해서 노드를 순회할 임시 포인터 temp에 리스트의 첫 번째 노드의
주소(L)을 지정
(2-2) while(temp.link != null) do temp <- temp.link;
- while 반복문을 수행하여 순회 포인터 temp가 노드의 링크 필드를 따라 이동하면서 링크필드가
null인 마지막 노드를 찾도록 함
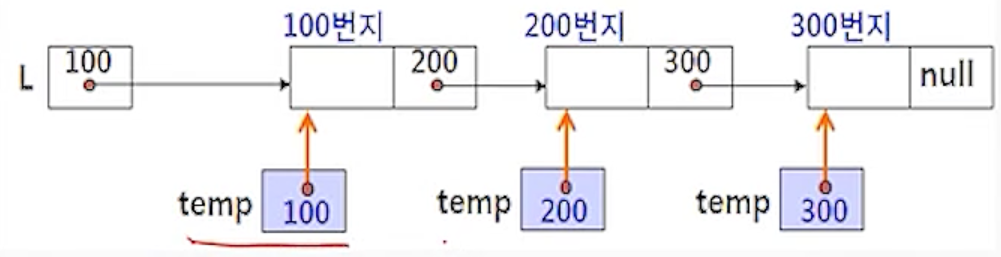
(2-3) tem.link <- new;
- 순회 포인터 temp가 가리키는 노드 즉, 리스트의 마지막 노드의 링크 필드(temp.link)에
삽입할 새 노드 new의 주소를 저장하여 리스트의 마지막 노드가 새 노드 new를 연결
2. 단순 연결 리스트의 삭제 알고리즘
deleteNode(L, pre)
if(L = null) then error; // (1) 공백 리스트인 경우
else{ // (2) 공백 리스트가 아닌 경우
old <- pre.link; // (2-1)
if (old = null) then return; // (2-2)
pre.link <- old.link; // (2-3)
}
returnNode(old); // (2-4)
end deleteNode()
1) 삭제 알고리즘 실행 단계
(1) if(L = null) then error;
- 삭제 연산을 수행하기 위해서는 반드시 하나 이상의 노드가 존재해야 함.
- 삭제 연산을 수행하기 전에 리스트 L이 공백 리스트인지를 검사하여 공백 리스트인 경우 에러 처리를 함
- underflow 처리
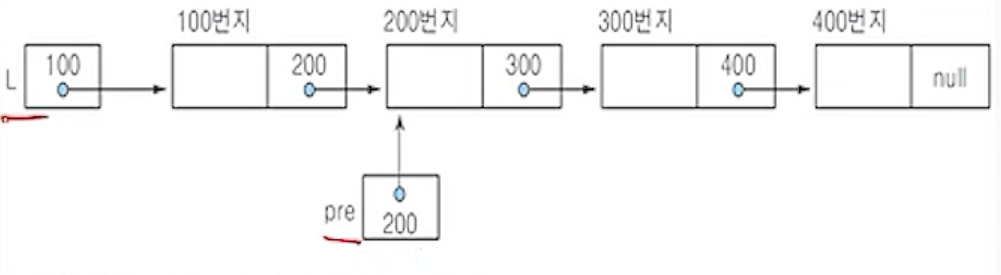
(2) 리스트 l이 공백이 아닌 경우
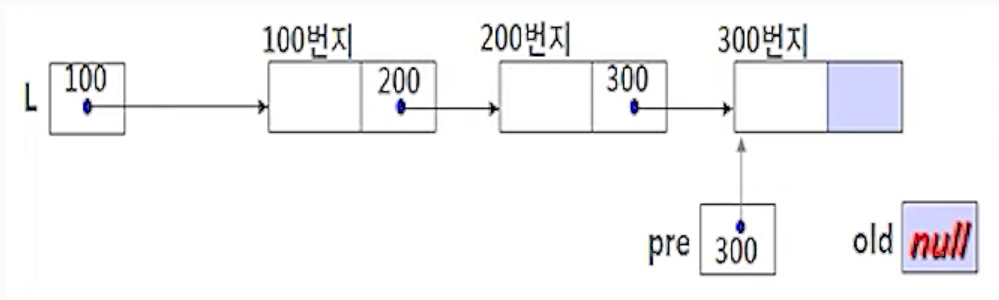
(2-1) old <- pre.link;
- 노드 old가 삭제할 노드를 가리키게 하기위해서 노드 pre의 링크 필드값(300)을 노드 oldd에 저장하여
포인터 old가 pre 다음 노드를 가리키도록 함.
(2-2) if (old = null) then return;
- 만약 노드 pre가 리스트의 마지막 노드였다면 노드 pre 다음에 삭제할 노드가 없다는 의미로 삭제 연산을
수행 하지 못하고 반환함
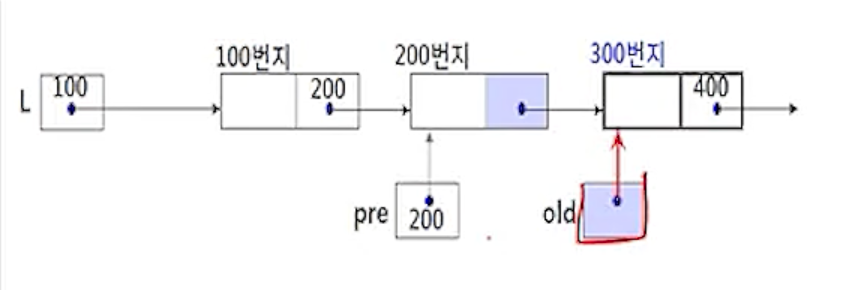
(2-3) pre.link <- old.link;
- 삭제할 노드 old의 다음 노드(old.link, 400)를 노드 pre의 다음 노드(pre.link)가 되도록 연결함
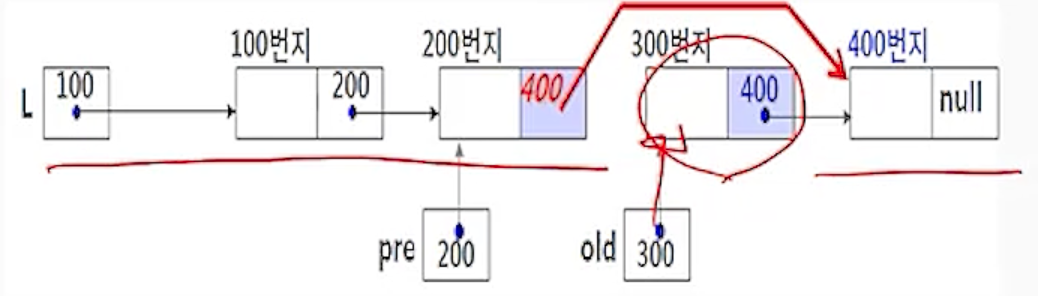
(2-4) returnNode(old);
- 삭제한 노드 old를 자유 공간 리스트에 반환
3. 단순 연결 시트의 노드 탐색 알고리즘
- 연결 리스트에서 원소값이 x인 노드를 탐색하려면 리스트의 노드를 처음부터 하니씩 순회하면서
노드의 데이터 필드값과 x를 비교하여 일치하는 노드를 찾음
searchNode(L, x)
temp <- L; // (1)
while(temp !=null) do{ // (2)
if(tem.data = x) then return temp;
temp <- temp.link;
}
return temp; // (3)
end searchNode()
- 리스트 L의 시작 주소를 노드 탐색을 위해 사용할 순회 포인터 temp에 저장하면서 포인터 temp의 시작 위치를
지정
- 순회 포인터 temp가 null이 아닌 동안 즉, temp가 가리키는 노드가 마지막 노드가 될 때까지 노드 temp
의 데이터 필드값이 x인지를 검사하여 x이면 그 노드의 주소를 반환하고 x가 아니면 링크를 따라 다음 노드로
순회 포인터 temp를 이동시킴
- while 반복문에서 x노드를 찾지 못하고 결국 리스트의 마지막 노드에서 while문 수행이 끝난 상태이므로
포인터 temp를 반환함.

댓글남기기