자료 구조 - 큐의 구현 1
1. 원형 큐의 이해
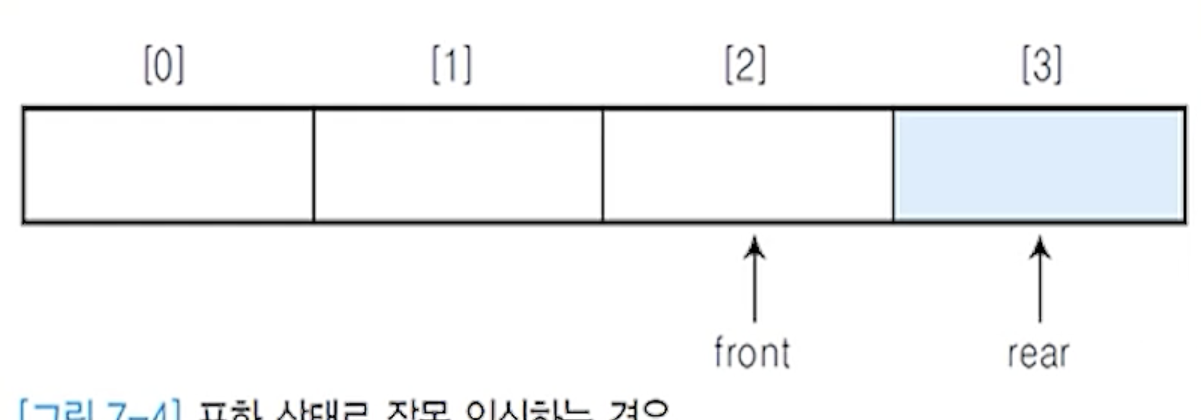
1) 선형 큐의 잘못된 포화상태 인식
- 큐에서 삽입과 삭제를 반복하면서 아래와 같은 상태일 경우, 앞부분에 빈자리가 있지만 rear = n - 1상태이므로
포화상태로 인식하고 더 이상의 삽입을 수행하지 않음
2) 선형 큐의 잘못된 포화상태 인식의 해결 방법
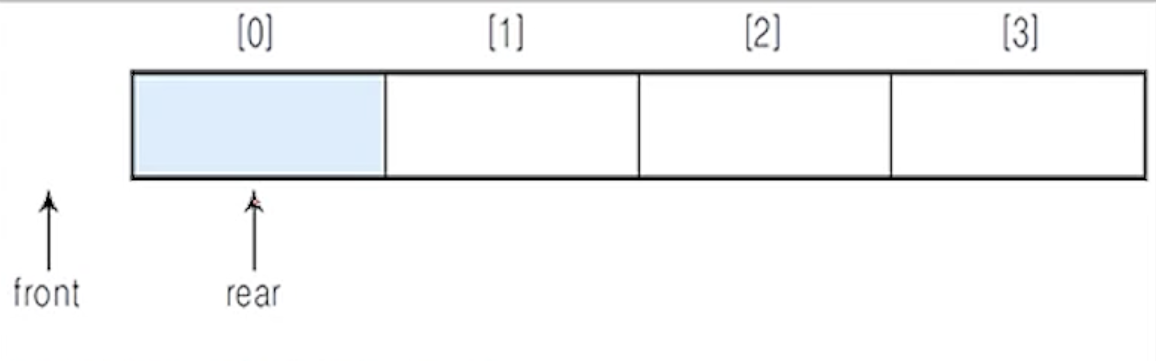
(1) 저장된 원소들을 배열의 앞부분으로 이동시키기
- 순차자료에서의 이동 작업은 연산이 복잡하여 효율성이 떨어짐
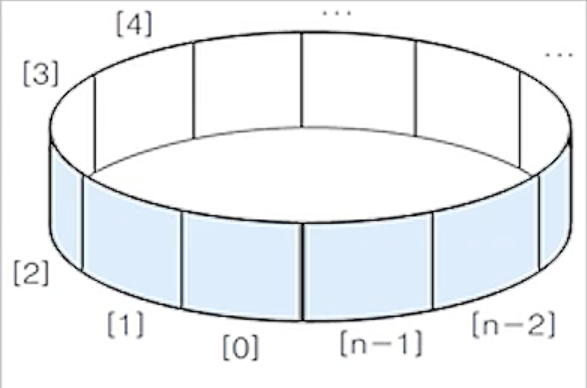
(2) 원형 큐 - 대표적인 방법
- 1차원 배열을 사용하면서 논리적으로 배열의 처음과 끝이 연결되어 있다고 가정하고 사용
2. 원형 큐의 구현
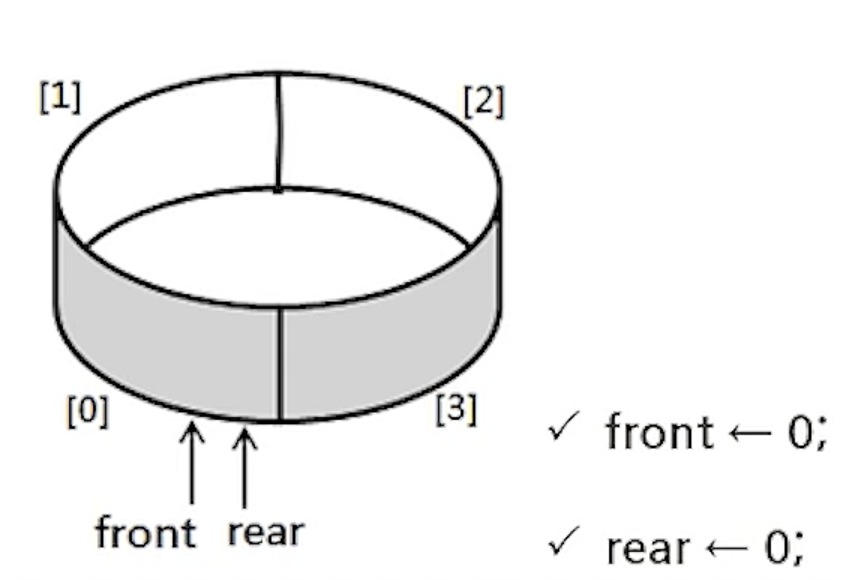
1) 원형 큐의 구조
- 초기 공백 상태 : front = rear = 0
- front와 rear의 위치가 배열의 마지막 인덱스 n-1에서 논리적인 다음 자리인 인덱스 0번으로 이동하기 위해서
나머지 연산자 mod를 사용
- 공백 상태와 포화 상태 구분을 쉽게 하기 위해서 front가 있는 자리는 사용하지 않고 항상 빈자리로 둠

2) 초기 공백 원형 큐 생성 알고리즘
- 크기가 n인 1차원 배열 생성
- front와 rear을 0으로 초기화
createQueue()
cQ[n];
front <- 0;
rear <- 0;
end createQueue()
3) 원형 큐의 공백 상태 검사 알고리즘과 포화상태 알고리즘
- 공백 상태 : front = rear
- 포화 상태 : 삽입할 rear의 다음 위치 = front의 현재 위치 (rear + 1) mod n = front
isEmpty(cQ)
if(front = rear) then return true;
else return false;
end isEmpty()
isFull(cQ)
if(((reat+1) mod n) = front) then return true;
else return false;
end isFull()
4) 원형 큐의 삽입 알고리즘
- rear의 값을 조정하여 삽입할 자리를 준비
- rear <- ( rear + 1 ) mod n;
- 준비한 자리
cQ[rear]에 원소 item을 삽입
5) 원형 큐의 삭제 알고리즘
- front의 값을 조정하여 삭제할 자리를 준비
- 준비한 자리에 있는 원소
cQ[front]를 삭제하고 반환
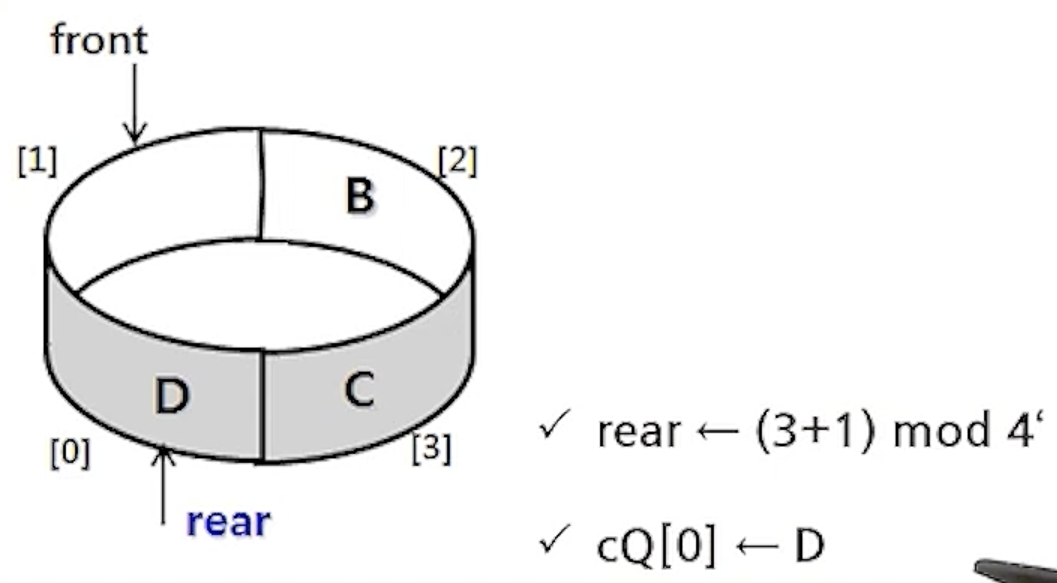
6) 원형 큐에서의 연산 과정
- createQueue();
- enQueue(cQ,A);
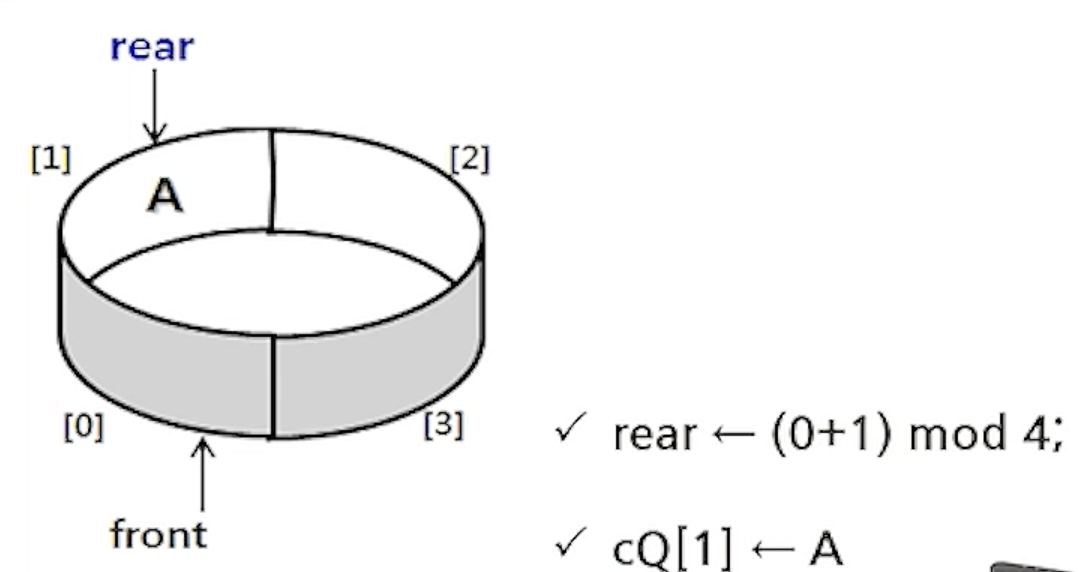
- enQueue(cQ,B);
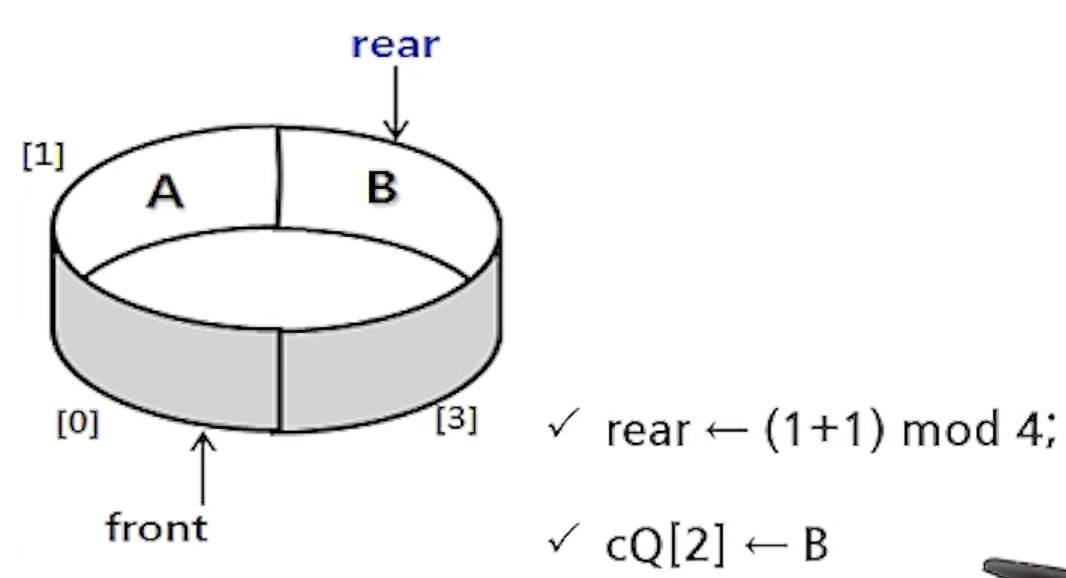
- deQueue(cQ);
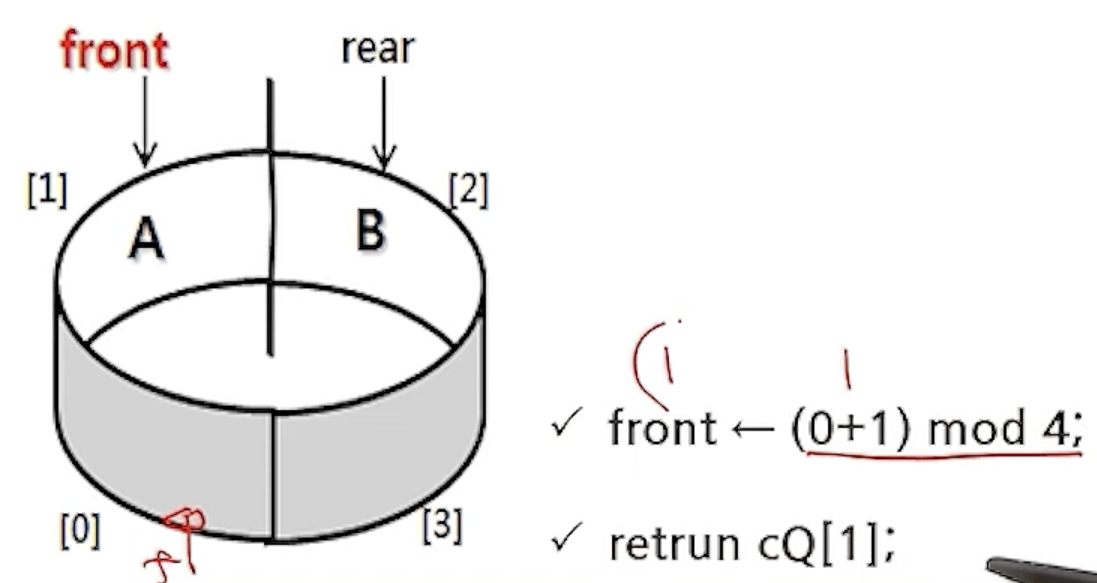
- enQueue(cQ,C);
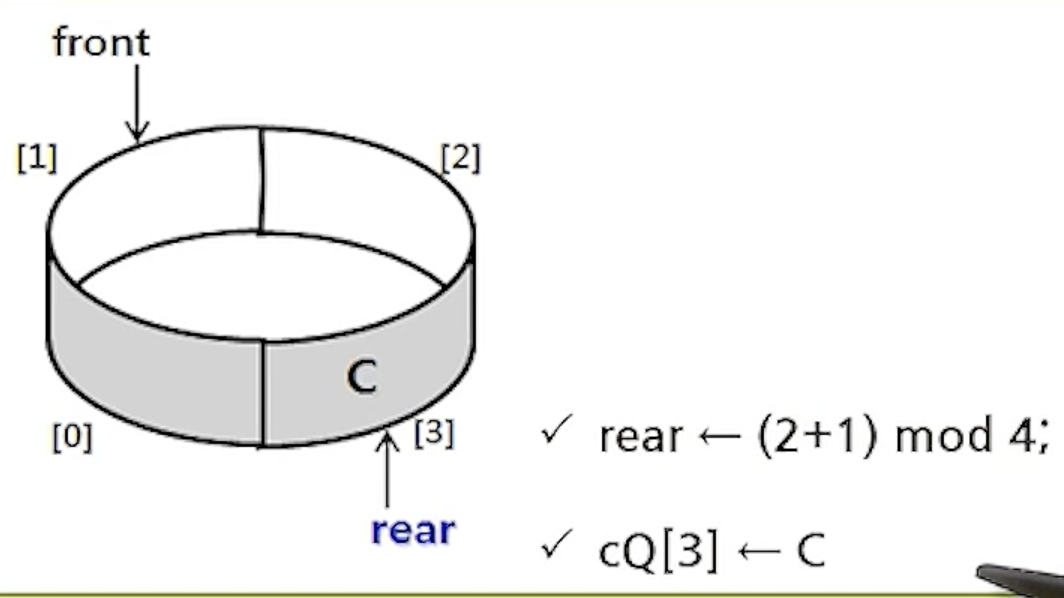
- enQueue(cQ,D);
3. 연결 큐의 이해와 규현
1) 연결 큐
(1) 순차 자료구조를 이용한 큐의 문제점
- 사용 크기가 제한됨
- 원소가 없는 경우에도 고정된 크기를 유지하고 있어 메모리 낭비
- 이것을 해결하기 단순 연결 리스트를 사용
(2) 단순 연결 리스트를 이용한 큐
- 큐의 원소 : 단순 연결 리스트의 노드
- 큐의 원소의 순서 : 노드의 링크 포인터로 연결
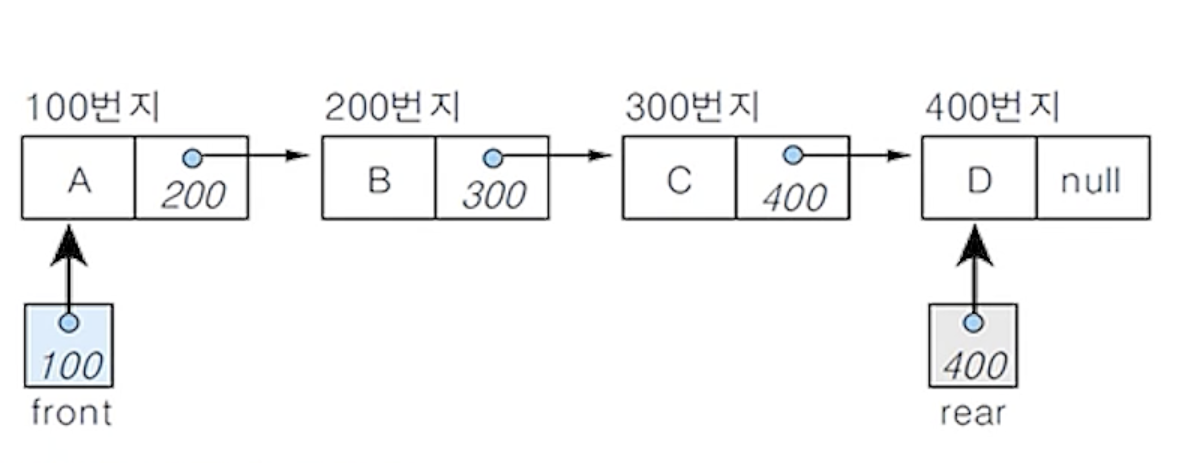
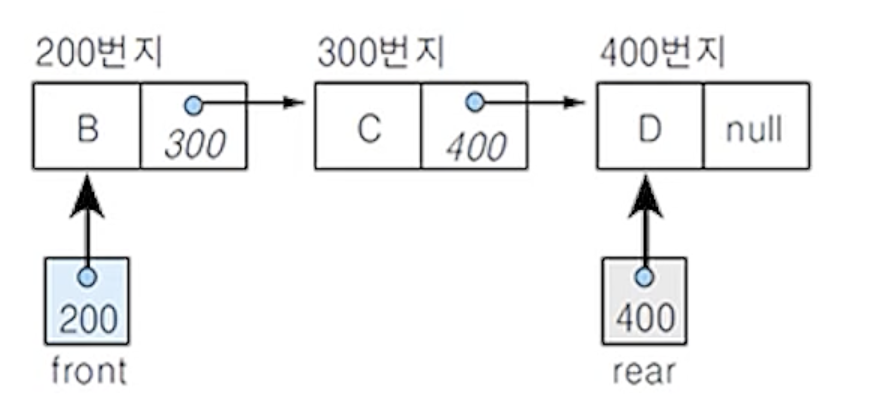
- 변수 front : 첫 번째 노드를 가리키는 포인터 변수
- 변수 rear : 마지막 노드를 가리키는 포인터 변수
- 초기 상태와 공백 상태 : front = rear = null
(3) 연결 큐의 구조
(4) 초기 공백 연결 큐 생성 알고리즘
- 초기화 : front = rear = null
createLinkedQueue()
front <- null;
rear <- null;
end createLinkedQueue()
(5) 공백 연결 큐 검사 알고리즘
- 공백 상태 : front = rear = null
isEmpty(LQ)
if( front = null ) then return true;
else return false;
end isEmpty()
(6) 연결 큐의 삽입 알고리즘
enQueue(LQ, item)
new <- getNode(); // (1)
new.data <- item; // (1)
new.link <- null; // (1)
if (front = null) then { // (2)
rear <- new;
front <- new;
}
else { // (3)
rear.link <- new;
rear = new;
}
end enQueue()
(6-1)
- 삽입할 새 노드를 생성하여 데이터 필드에 item을 저장
- 삽입할 노드는 연결 큐의 마지막 노드가 되어야 하므로 링크 필드에 null을 저장함
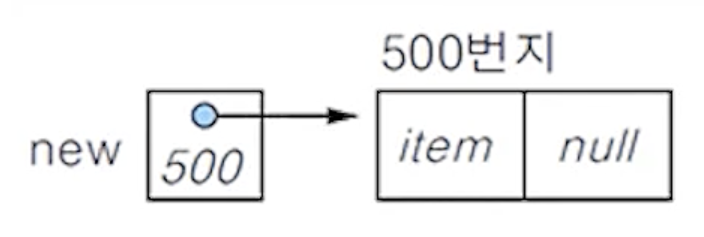
(6-2)
- 새노드를 삽입하기 전에 연결 큐가 공백인지 검사
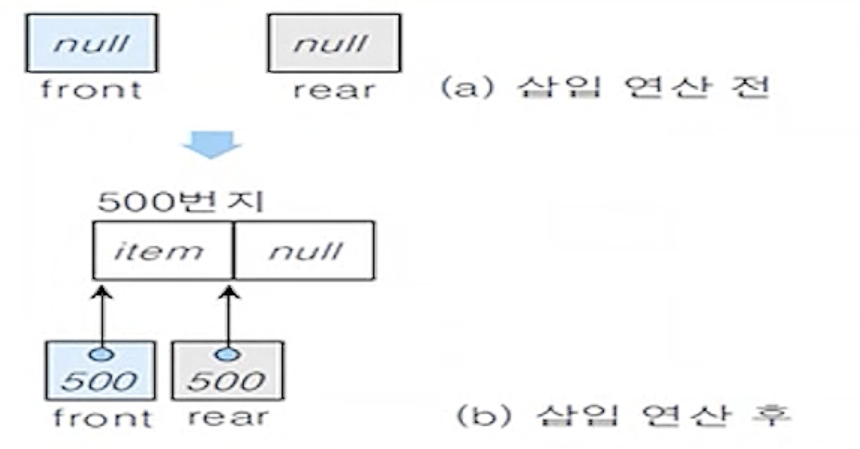
(6-3)
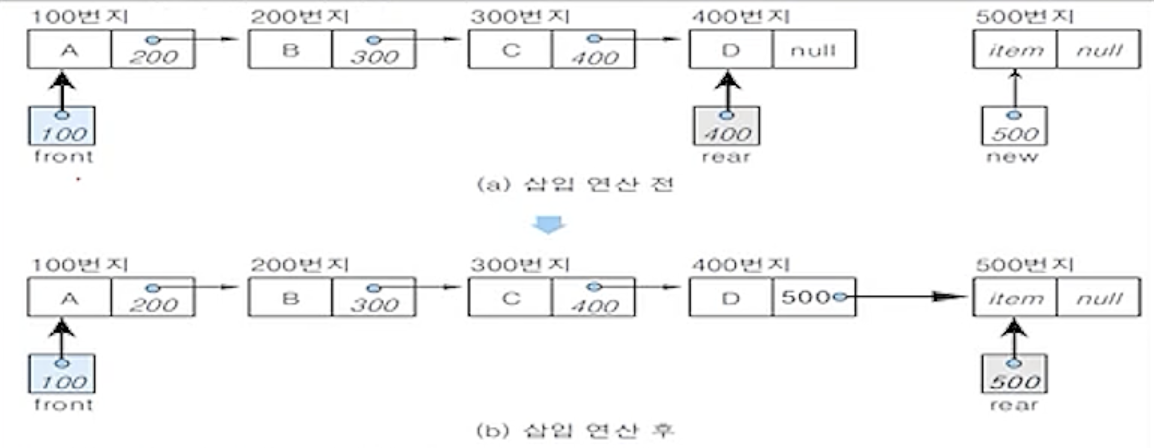
(7) 연결 큐의 삭제 알고리즘
deQueue(LQ)
if(isEmpty(LQ)) then Queue_Empty();
else{
old <- front; // (1)
item <- front.data;
front <- front.link; // (2)
if (isEmpty(LQ)) then rear <- null; // (3)
returnNode(old);
return item;
}
end deQueue()
delete(LQ)
if(isEmpty(LQ)) then Queue_Empty();
else{
old <- front;
front <- front.link;
if(isEmpty(LQ)) then rear <- null;
returnNode(old);
}
end delete()
(7-1)
- 삭제 연산에서 삭제할 노드는 큐의 첫 번째 노드
- 삭제 연산에서 삭제할 노드는 큐의 첫 번째 노드로서 포인터 front가 가리키고 있는 노드
- front가 가리키는 노드를 포인터 old가 가리키게 하여 삭제할 노드를 지정함
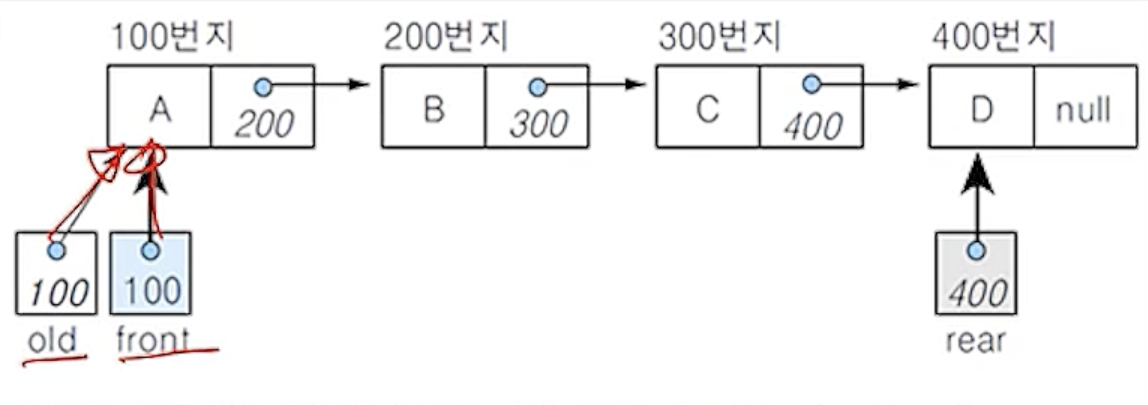
(7-2)
- 삭제연산 후 포인터 front를 재설정함
- 삭제연산 후에는 현재 front 노드의 다음 노드가 front 노드(첫번째 노드)가 되어야 하므로,
포인터 front를 재설정함
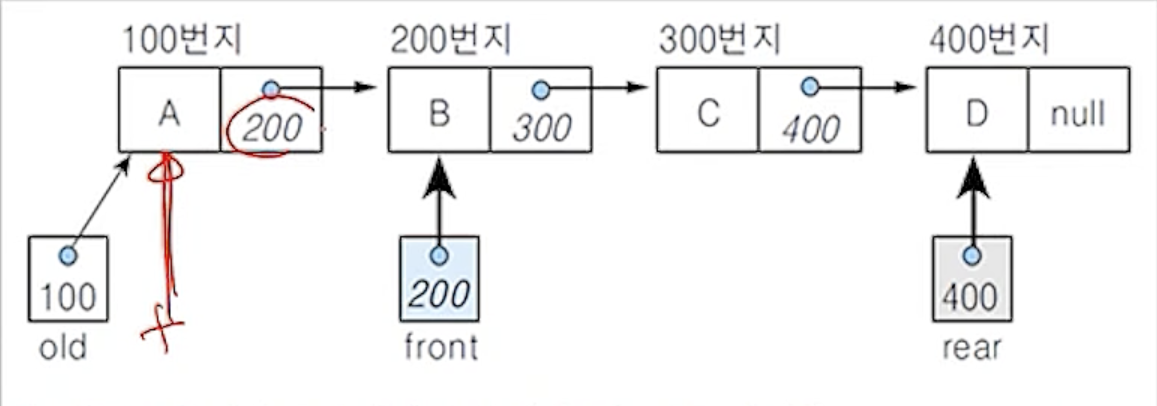
(7-3)
- 삭제 연산 후에 공백 큐가 되는 경우
- 현재 큐에 노드가 하나뿐이어서 삭제연산 후에 공백 큐가 되는 경우
- 큐의 마지막 노드가 없어지므로 포인터 rear를 null로 설정함
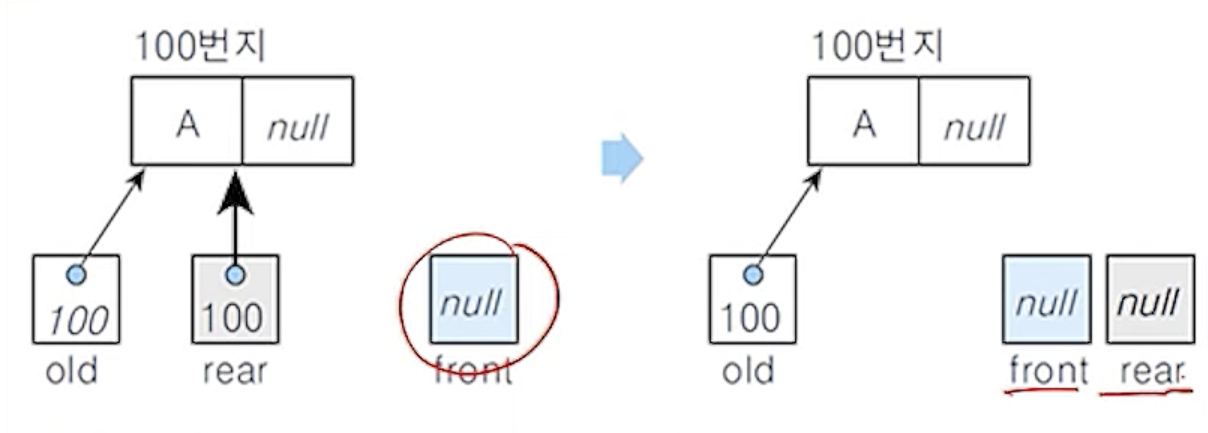
(7-4)
- 메모리 공간을 시스템에 반환
- 포인터 old가 가리키고 있는 노드를 삭제하고, 메모리 공간을 시스템에 반환함
(8) 연결 큐의 검색 알고리즘
- 연결 큐의 첫 번째 노드, 즉 front 노드의 데이터 필드값을 반환
peek(LQ)
if(isEmpty(LQ)) then Queue_Empty()
else return (front.data);
end peek()

댓글남기기