목차
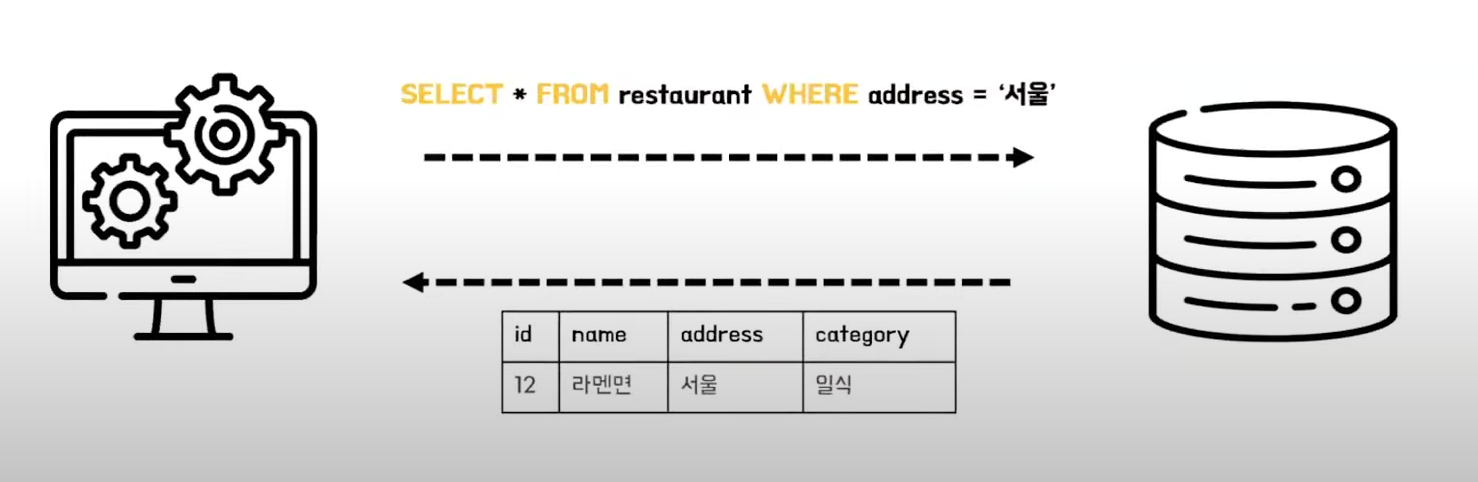
1. Index란
- 데이터베이스의 검색 속도를 향상 시키기 위한 자료 구조
2. B-tree
- 균형 트리
- 탐색 트리 (정렬)
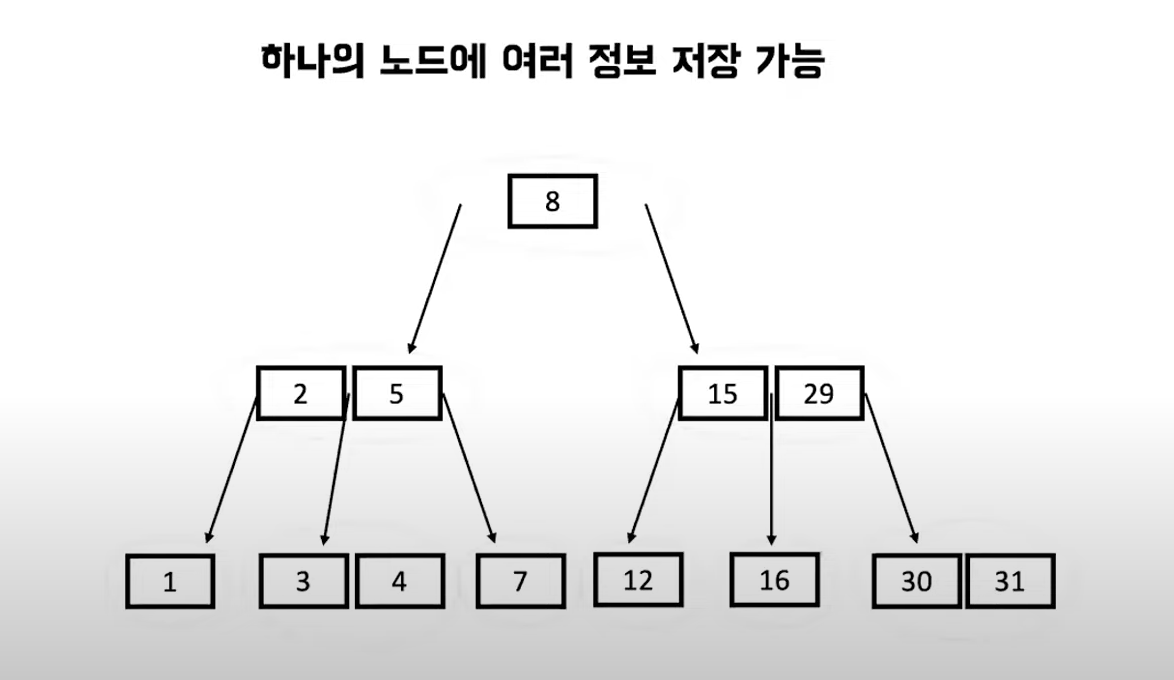
- 하나의 노드에 여러 정보 저장 기능
- 두개 이상의 자식을 가질 수 있다.
1) 균형 트리
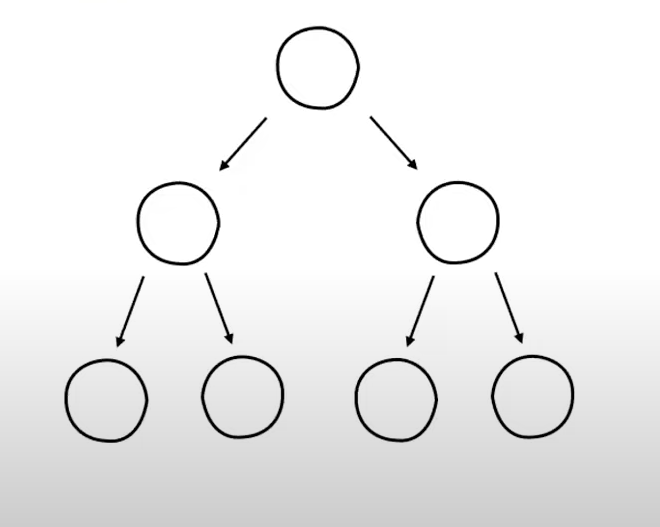
2) 탐색 트리
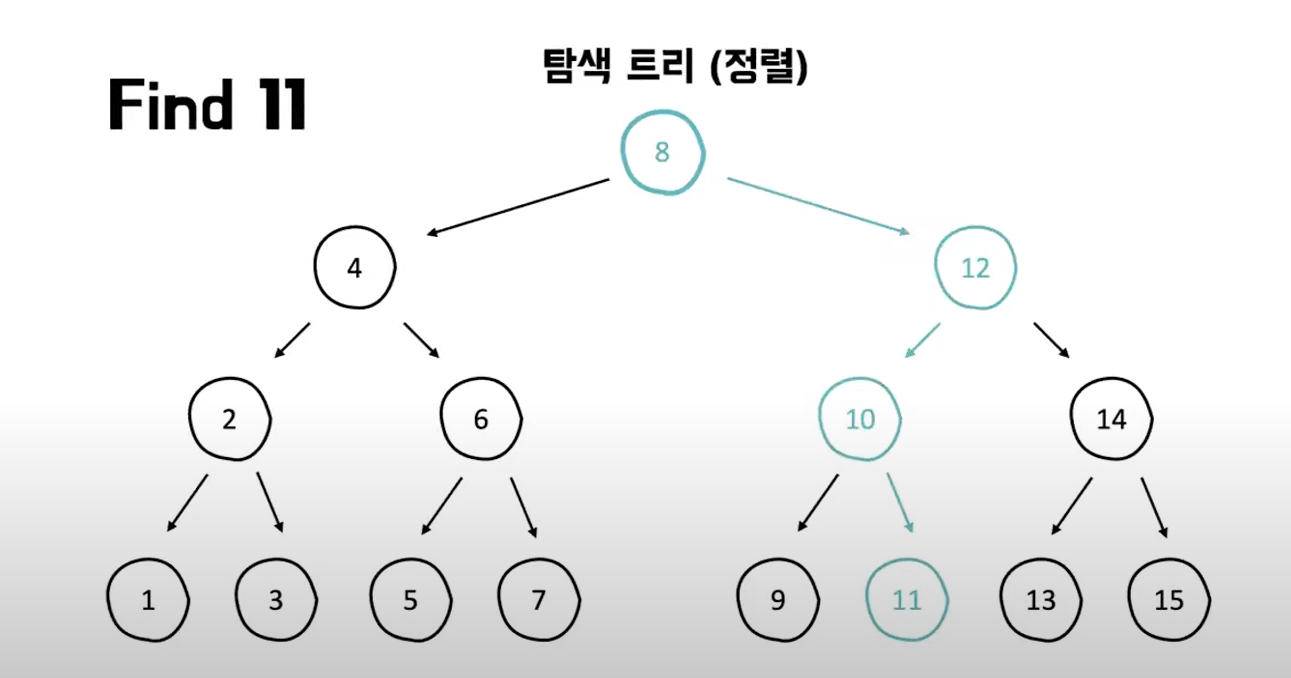
- 검색성의 최대한 끌어올리기 때문에 쓰기성능을 떨어짐
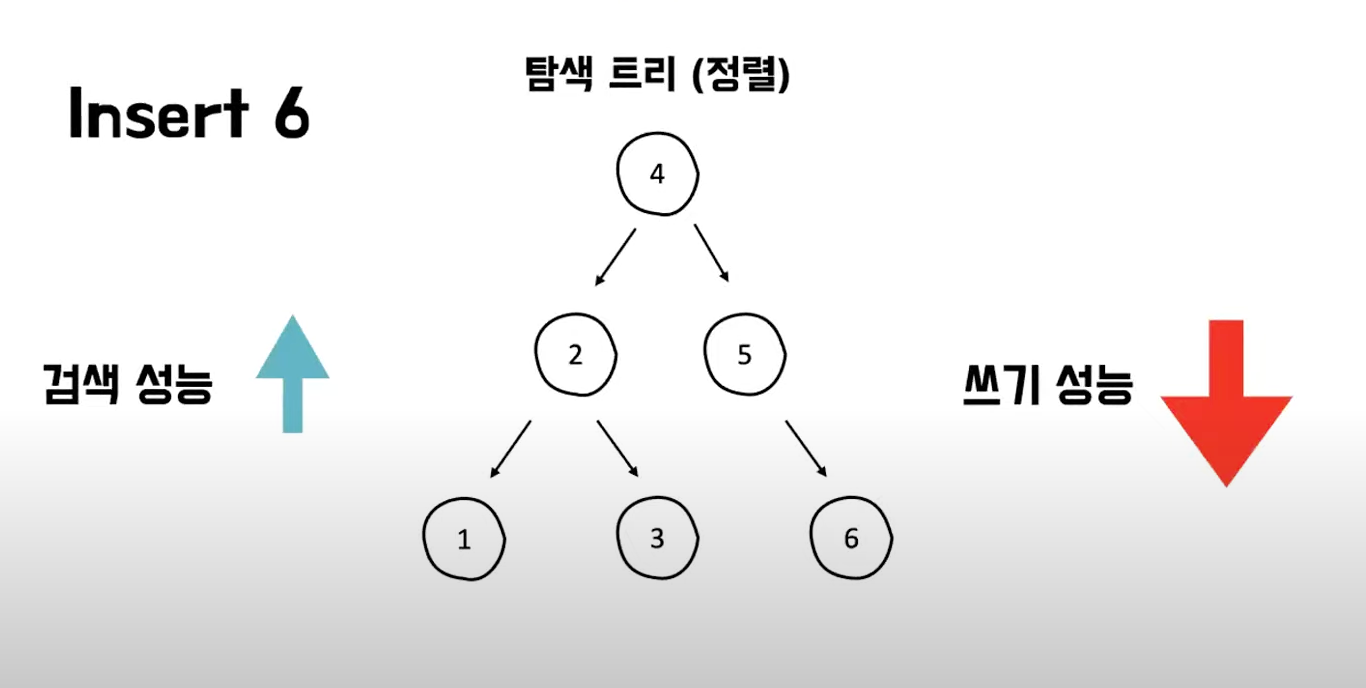
3) 하나의 노드에 여러 정보 저장 기능 , 두개 이상의 자식을 가질 수 있음
3. Index의 종류
- Clustered Index
- Non-clustered Index
1) Clustered Index ( = PK Index)
- 실제 데이터와 군집(강한 연관)을 이루는 인덱스
- 데이터가 테이블에 물리적으로 저장되는 순서를 정의
- PK로 설정하면, 자동으로 생성 or Unique and Not null 제약 조건을 생성
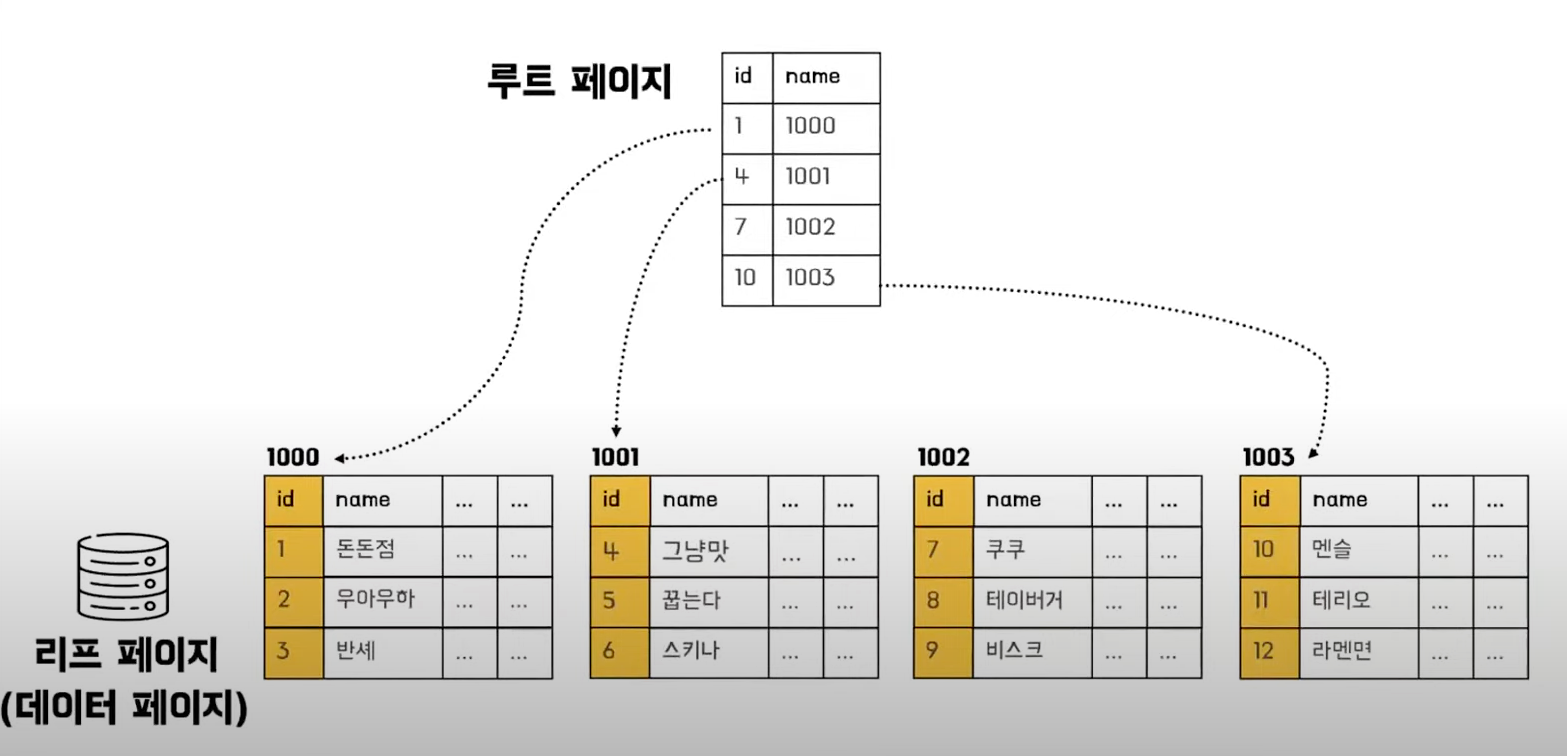
- 데이터 정렬
- Index의 리프 페이지가 실제 데이터
- 테이블당 1개만 존재
2) Non-clustered Index
CREATE INDEX name_index ON restaurant(name)
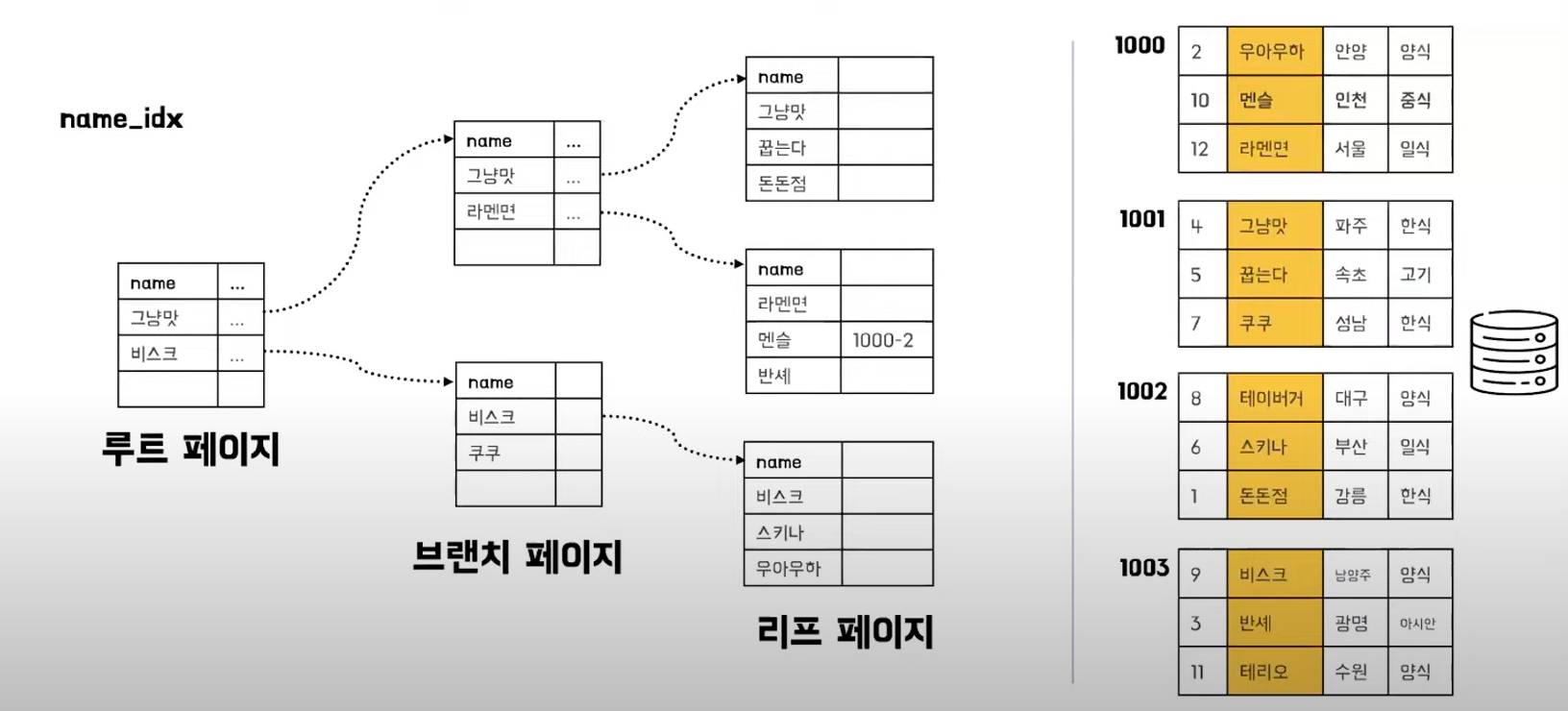
- 인덱스와 데이터 페이지가 따로 존재
- 리프 페이지에선 데이터주소를 가짐
- 데이터페이지가 정렬되지 않아도 된다.
- 한 테이블에 여러개가 존재할 수 있다.
4. Clustered & Non-clustered
- PK column을 설정하여 테이블을 생성한 뒤 ( => Clustered Index)
- 자주 발생하는 조회 column에 대해 index를 추가하면 (=> Non-Clustered Index)
- 이런 케이스에선 어떻게 동작할까요
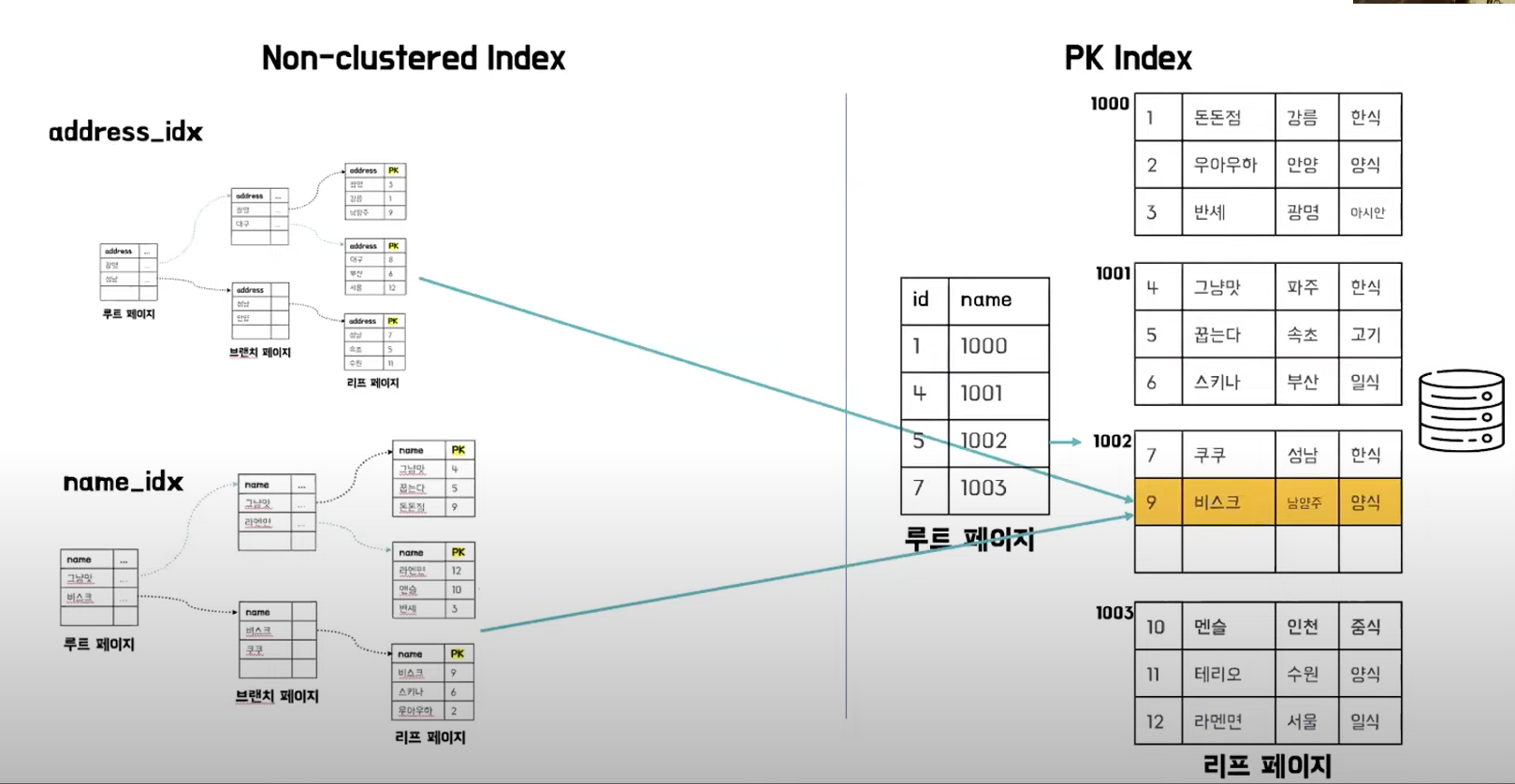
Index는 어디에 ?
- WHERE, JOIN 조건에 자주 발생하는 컬럼들
- INSERT, UPDATE, DELETE 적게 발생하는 컬럼
- 중복도가 낮은 컬럼
- 범위 검색이 적은 컬럼
- 데이터가 많은 테이블
출처
로이스의 Index

댓글남기기