
Database 13. 성능 데이터 모델링
성능 데이터 모델링
프로젝트 단계
비용
분석/설계 구현 테스트 운영
시간
성능 데이터 모델링 정의
- 설계단계의 데이터 모델링 때부터 정규화, 반정규화, 테이블통합, 테이블분할,
조인구조, PK, FK 등 여러가지 성능과 관련된 사항이 데이터 모델링에 반영 될
수 있도록 하는 것.
성능 데이터 모델링 고려사항
- 데이터 모델링을 할 떄 정규화를 정확하게 수행한다.
분산시키는 효과가 있기 때문에 그 자체로 성능을 향상시키는 효과가 있음.
- 용량과 트랜잭션의 유형에 따라 반 정규화를 수행한다.
- 이력 모델의 조정, PK/FK 조정등을 수행한다.
- 성능관점에서 데이터 모델을 검증한다.
정규화를 통한 성능 향상 전략
- 결정자에 의해 함수적 종속을 가지고 있는 일반 속성을 의존자로 하여
입력/수정/삭제 하는 것임. - 한 테이블의 데이터 용량이 최소화되는 효과가 있음.
정규화된 데이터 모델
조회
==> 처리조건 ==> 성능 향상
성능 저하
입력 수정 삭제
==> 처리조건 ==> 성능 향상
정규화 용어
정규화 (Normalization)
- 관계형 데이터 베이스 테이블의 삽입, 삭제, 갱신 이상(anomaly) 현상 발생을 최소화 하기
위해 좀 더 나은 단위의 테이블로 설계 하는 과정.
함수적 종속성 (FD : Functional Dependency)
- 테이블의 특정 컬럼 A의 값을 알면 다른 컬럼 B값을 알 수 있을 때,
털럼 B는 컬럼 A에 함수적 종속성이 있다고 함.
ex) 고객명은 고객주민등록번호에 함수적 종속성이 있음
결정자
- 함수적 종속성에서, 컬럼 A를 결정자라고 함.
ex) 주민등록번호는 결정자
정규화 이론
- 1차, 2차, 3차, 보이스코드정규화는 함수종속성에 근거하여 정규화를 수행함.
1차 정규화
- 함수종속, 복수의 송성값을 갖는 속성을 분리, 속성의 원자성 확보
2차 정규화
- 함수종속, 주식별자에 완전 종속적이지 않은 속성의 분리
- 부분종속 속성을 분리
3차 정규화
- 함수종속, 일반속성에 종속적인 속성의 분리
제 1 정규형
- 모든 속성은 원자 값을 가져야 함.
- 다중 값을 가질 수 있는 속성은 분리되어야 함.
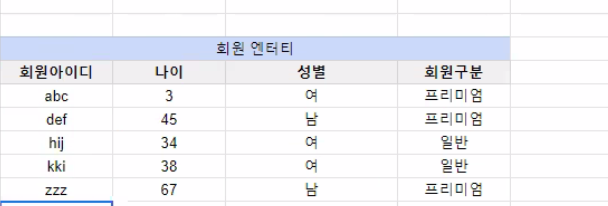
제 1 정규형 위반 예시
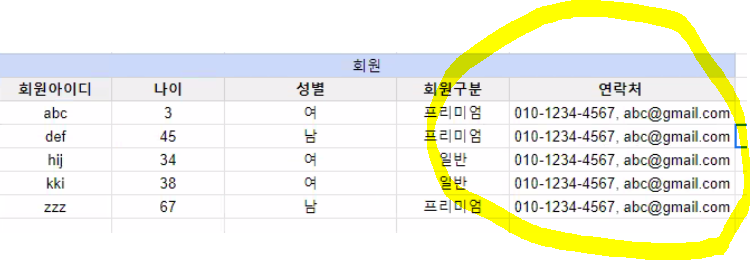
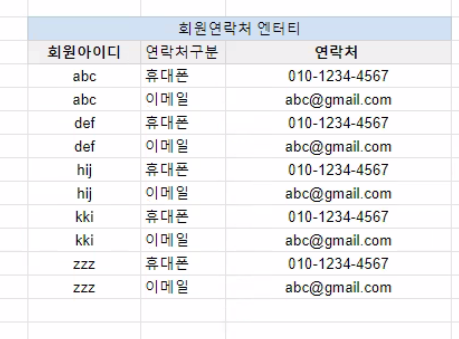
분리
- 연락처 속성을 삭제
- 회원 연락처 엔터티 추가
제 2 정규형
- 제 1정규형을 만족하는 상태에서 모든 Non-key 컬럼은 기본키 전체에 종속되어야 함
- 기본 키에 종속적이지 않거나 기본 키 일부 컬럼(들)에만 종속적인 컬럼은 분리되어야 함.
제 2 정규형 위반 예시
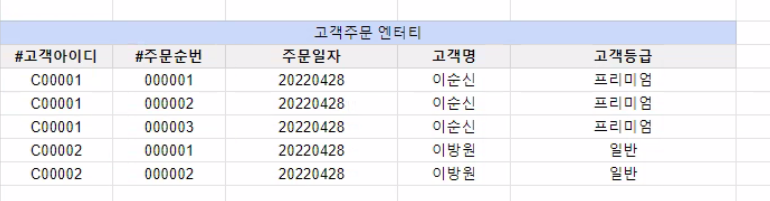
분리
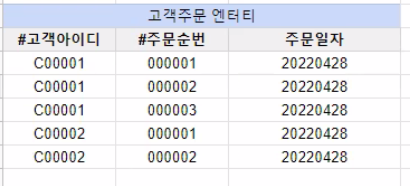
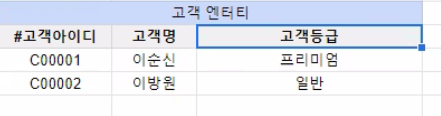
- 모든 속성이 식별자만으로 함수 종속을 가짐
- 식별자의 일부에만 종속하는 속성 없음
제 3 정규형
- 제 2정규형을 만족하는 상태에서 일반속성들간에도 종속관계가 존재하지 않아야 함
- 일반 속성들 간 종속 관계가 존재하는 것들은 분리되어야 함.
제 3 정규형 위반 예시
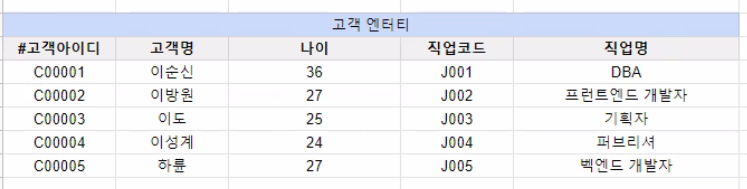
- 식별자를 제외한 일반 속성끼리 함수 종속이 발생
- 식별자 이외의 키 간 발생하는 함수의 종속
분리
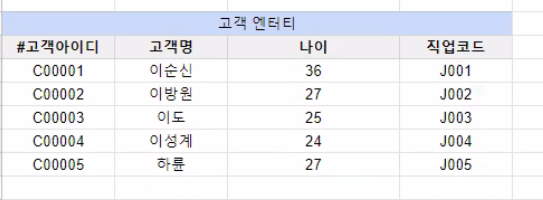
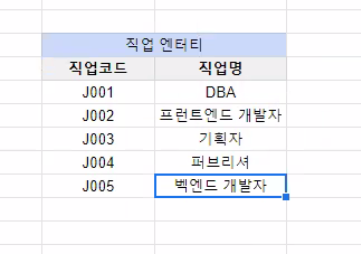
- 직업 엔터티를 추가하여 일반 속성 끼리의 함수 종속을 제거함
정규화 성능
- 정규화를 수행해서 조인이 발생하게 되더라도 효유적인 인덱스 사용을 통해
조인 연산을 수행하면 성능상 단점은 거의 없다.
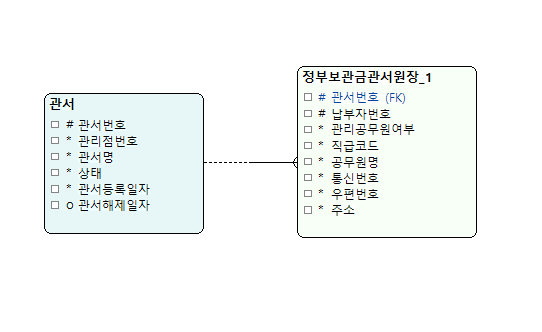
예시

정규화
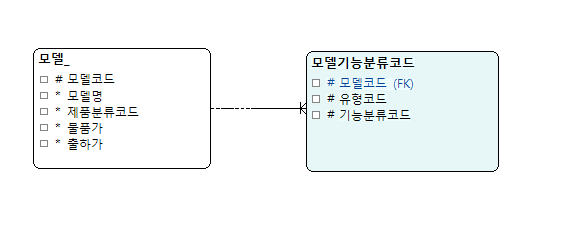
예시 2

정규화
댓글남기기